
그래프 색 바꾸는 게 너무 재밌어
근데 막상 빨리 바꾸려니까 생각이 안나서 레드, 옐로우, 그린 돌려쓰다가 핑크도 쓴다.
EDA 데이터 구조 파악
1. 데이터 구조 파악(EDA, 탐색적 데이터 분석, Exploratory Data Analysis)
- 데이터 분석을 수행하기 전에 데이터의 구조를 파악하고 특성을 이해하는 과정
1) EDA의 주요 목적
- 데이터의 기본 정보 파악: 데이터 크기, 컬럼 수, 데이터 타입 등을 확인.
- 결측치 및 이상치 탐색: 누락된 값과 비정상적인 값을 찾아 적절한 처리 방안을 결정.
- 기술통계를 이용한 데이터 요약: 평균, 중앙값, 표준편차 등 주요 통계량을 분석.
- 데이터의 분포 확인: 데이터가 정규분포를 따르는지 여부 등을 시각적으로 확인.
- 변수 간 관계 분석: 변수 간 상관관계를 분석하여 데이터의 패턴을 이해
2) 데이터의 기본 정보 확인 - 기본 구조 확인
import pandas as pd
# 데이터 로드 (예제 데이터)
df = pd.read_csv("sample_data.csv")
# 데이터 크기 확인 (행, 열 개수)
print(f"데이터 크기: {df.shape}")
# 컬럼명 확인
print(f"컬럼명: {df.columns.tolist()}")
# 데이터 타입 확인
print(df.info())
# 상위 5개 행 출력
print(df.head())
3) 결측치 및 이상치 탐색
(1) 결측치 탐색
# 각 컬럼별 결측치 개수 확인
print(df.isnull().sum())
# 결측치 처리 방법
# 평균으로 대체
df['나이'] = df['나이'].fillna(df['나이'].mean())
# 최빈값으로 대체
df['소득'] = df['소득'].fillna(df['소득'].median())
- 결측치 처리 방법
- 삭제: 데이터 수가 많고 결측치가 적다면 해당 행을 삭제.
- 대체:
- 수치형 데이터 → 평균, 중앙값, 최빈값으로 채우기
- 범주형 데이터 → 최빈값으로 채우기
- KNN이나 회귀모델을 사용하여 예측 값으로 대체 가능
(2) 이상치 탐색
- 이상치는 데이터를 왜곡할 수 있기 때문에 제거하거나 조정해야 합니다.
- 이상치 탐색 방법
- 박스플롯(Box Plot) 활용: 사분위수를 기반으로 이상치를 탐색.
- Z-score 활용: 데이터가 평균에서 얼마나 벗어났는지 확인.
import matplotlib.pyplot as plt
import seaborn as sns
# 박스플롯으로 이상치 확인
plt.figure(figsize=(6, 4))
sns.boxplot(x=df['소득'])
plt.title("소득 이상치 탐색")
plt.show()
from scipy import stats
# Z-score 계산
df["소득_Z"] = stats.zscore(df["소득"])
# Z-score가 3 이상인 데이터 조회
outliers = df[df["소득_Z"].abs() > 3]
print(outliers)
4) 데이터 분포 확인
(1) 히스토그램을 이용한 데이터 분포 확인
- 데이터가 정규분포를 따르는지 확인 가능.
plt.figure(figsize=(6, 4))
sns.histplot(df["소득"], bins=30, kde=True)
plt.title("소득 분포")
plt.show()
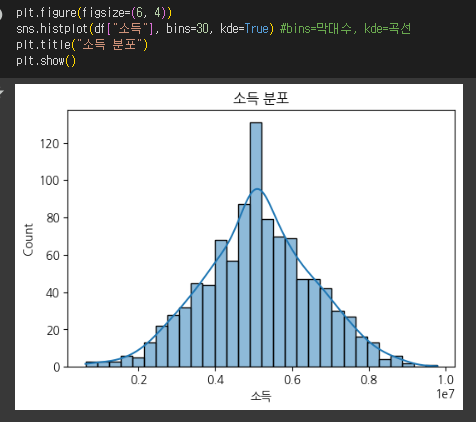
- 점들이 직선에 가까우면 정규성을 띄고 있음을 의미함.
import scipy.stats as stats
import numpy as np
import matplotlib.pyplot as plt
stats.probplot(df["소득"].dropna(), dist="norm", plot=plt)
plt.title("QQ-Plot")
plt.show()
5) 변수 간 관계 분석
- 변수 간 관계를 확인하면 데이터의 패턴을 파악하는 데 도움이 된다.
(1) 상관계수 계산
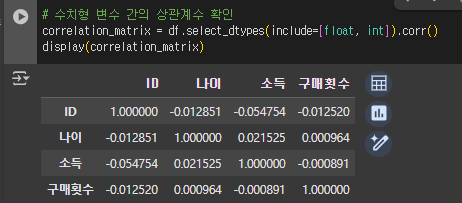
# 수치형 변수 간의 상관계수 확인
correlation_matrix = df.select_dtypes(include=[float, int]).corr()
print(correlation_matrix)
(2) 상관 행렬 히트맵 시각화
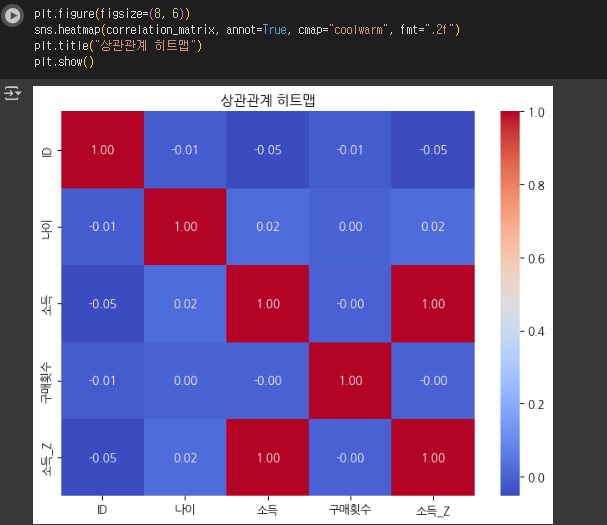
- 1에 가까울수록 양의 상관관계, -1에 가까울수록 음의 상관관계를 가짐.
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm", fmt=".2f")
plt.title("상관관계 히트맵")
plt.show()
6) 변수 간 관계 시각화
(1) 산점도를 활용한 관계 분석
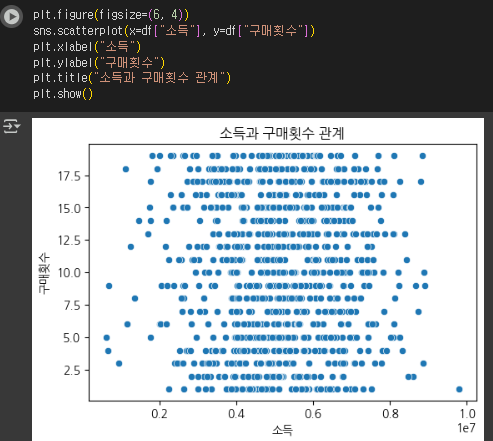
- 점들이 특정 패턴을 보이면 두 변수 간 관계가 있다고 볼 수 있음.
plt.figure(figsize=(6, 4))
sns.scatterplot(x=df["소득"], y=df["구매횟수"])
plt.xlabel("소득")
plt.ylabel("구매횟수")
plt.title("소득과 구매횟수 관계")
plt.show()
(2) 범주형 변수 분석
- 범주형 변수(예: 성별)와 수치형 변수(예: 구매금액)의 관계를 분석할 때 박스플롯을 활용할 수 있음.
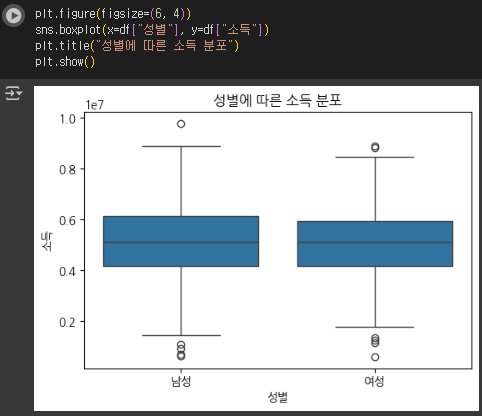
plt.figure(figsize=(6, 4))
sns.boxplot(x=df["성별"], y=df["소득"])
plt.title("성별에 따른 소득 분포")
plt.show()
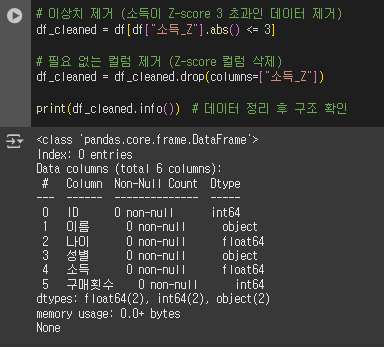
7) 데이터 정리 및 이상치 제거
- EDA를 통해 발견한 문제들을 해결하기 위해 데이터를 정리한다.
# 이상치 제거 (소득이 Z-score 3 초과인 데이터 제거)
df_cleaned = df[df["소득_Z"].abs() <= 3]
# 필요 없는 컬럼 제거 (Z-score 컬럼 삭제)
df_cleaned.drop(columns=["소득_Z"], inplace=True)
print(df_cleaned.info()) # 데이터 정리 후 구조 확인
2. 그로스 마케팅(Growth Marketing) 관점에서 EDA를 활용한 데이터 분석
- 그로스 마케팅에서는 데이터를 기반으로 고객 행동 분석, 전환율 최적화, 마케팅 ROI 분석 등을 수행해야 한다.
- EDA(탐색적 데이터 분석)를 통해 고객의 행동 패턴을 시각적으로 분석하고 인사이트를 도출하는 것이 중요하다.
1) EDA를 활용한 그로스 마케팅 분석 시나리오
| 분석 항목 | 설명 | 활용 그래프 |
| 신규 고객 vs 기존 고객 비율 | 신규 유입과 기존 고객의 비율 분석 | 파이 차트(Pie Chart) |
| 고객별 LTV 분석 | 고객 생애 가치(Lifetime Value) 분석 | 히스토그램(Histogram) |
| 이탈률(Churn Rate) 분석 | 이탈한 고객과 유지된 고객 비교 | 박스플롯(Box Plot) |
| 광고 채널별 전환율 | 광고 채널별 고객 전환율 비교 | 바 차트(Bar Chart) |
| 소득 vs 구매액 상관관계 | 소득이 높은 고객이 구매를 많이 하는지 분석 | 산점도(Scatter Plot) |
- 시나리오 개요
- 한 온라인 쇼핑몰에서 고객 데이터를 활용하여 그로스 마케팅 전략을 개선하고자 합니다.
특히, 신규 고객의 행동 패턴을 파악하고, 충성 고객을 분석하여 재구매율을 높이는 전략을 세우려 합니다.
- 한 온라인 쇼핑몰에서 고객 데이터를 활용하여 그로스 마케팅 전략을 개선하고자 합니다.
- 데이터셋 구조
| 컬럼명 | 설명 |
| 고객ID | 고객 고유 ID |
| 신규고객여부 | 신규 고객(1)인지 기존 고객(0)인지 표시 |
| LTV | 고객 생애 가치 (Lifetime Value) |
| 이탈여부 | 고객이 이탈했으면 1, 유지되었으면 0 |
| 광고채널 | 유입된 광고 채널 (구글, 페이스북, 인스타그램, 유튜브, 블로그 등) |
| 소득 | 고객의 월 소득 |
| 총구매금액 | 해당 고객이 현재까지 쇼핑몰에서 구매한 총 금액 |
2) EDA를 활용한 데이터 정리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import koreanize_matplotlib
# 랜덤 시드 고정
np.random.seed(42)
# 데이터 크기 설정
num_customers = 1000
# 고객 데이터 생성
df = pd.DataFrame({
"고객ID": range(1, num_customers + 1),
"신규고객여부": np.random.choice([0, 1], size=num_customers, p=[0.7, 0.3]), # 70% 기존, 30% 신규
"LTV": np.random.exponential(scale=50000, size=num_customers), # 고객 생애 가치(Lifetime Value)
"이탈여부": np.random.choice([0, 1], size=num_customers, p=[0.8, 0.2]), # 80% 유지, 20% 이탈
"광고채널": np.random.choice(["구글", "페이스북", "인스타그램", "유튜브", "블로그"], size=num_customers),
"소득": np.random.normal(loc=5000000, scale=1500000, size=num_customers), # 월 소득
"총구매금액": np.random.normal(loc=1000000, scale=500000, size=num_customers) # 총 구매 금액
})
# 일부 데이터 정리
df["소득"] = np.abs(df["소득"]) # 음수 방지
df["총구매금액"] = np.abs(df["총구매금액"]) # 음수 방지
3) 데이터 분석 및 그래프 시각화
(1) 신규 고객 vs 기존 고객 비율 분석 (파이 차트)
plt.figure(figsize=(6, 6))
df["신규고객여부"].value_counts().plot.pie(autopct="%.1f%%", labels=["기존 고객", "신규 고객"], colors=["skyblue", "lightcoral"])
plt.title("신규 고객 vs 기존 고객 비율")
plt.ylabel("")
plt.show()
- 활용 인사이트
- 신규 고객이 차지하는 비율을 확인하고, 고객 확보 전략을 개선하는 데 활용.
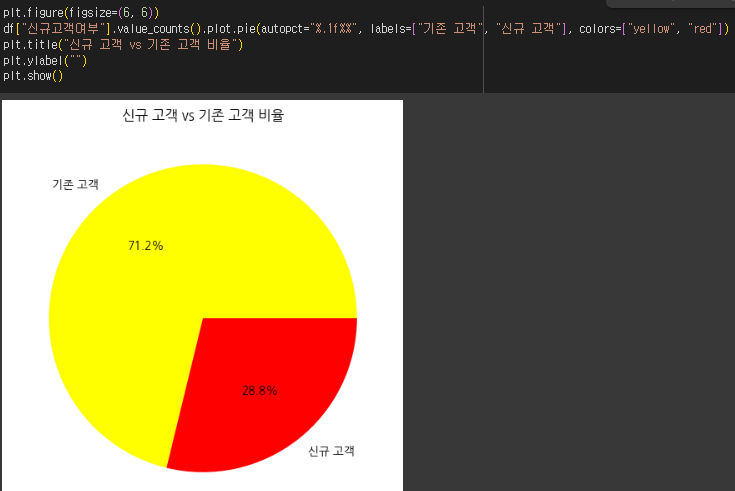
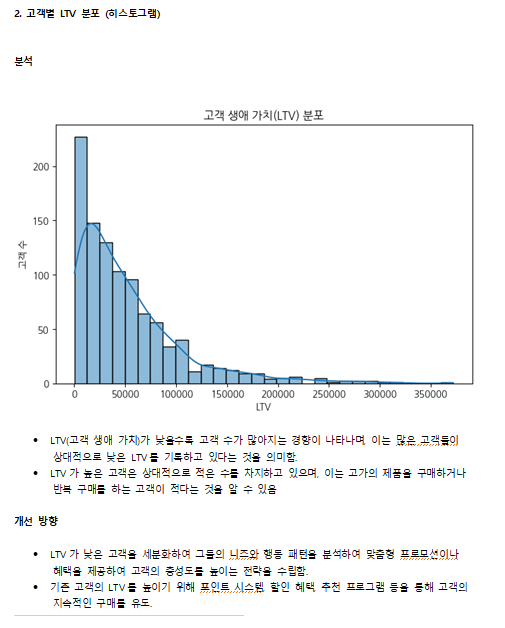
(2) 고객별 LTV 분포 (히스토그램)
plt.figure(figsize=(8, 5))
sns.histplot(df["LTV"], bins=30, kde=True)
plt.title("고객 생애 가치(LTV) 분포")
plt.xlabel("LTV")
plt.ylabel("고객 수")
plt.show()
- 활용 인사이트
- LTV가 높은 고객에게 추가적인 마케팅 비용을 투자하여 VIP 고객을 확보할 수 있음.
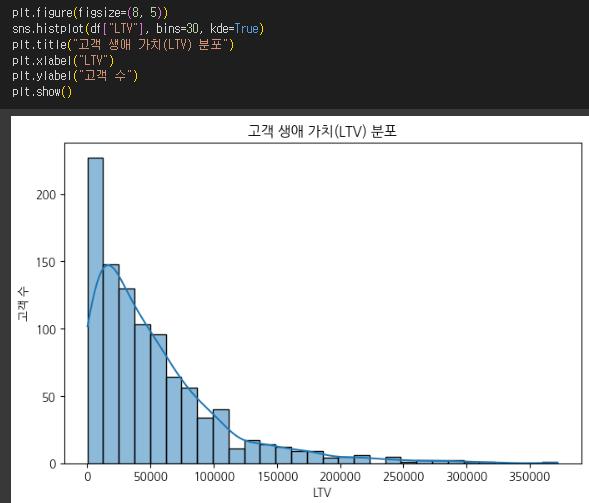
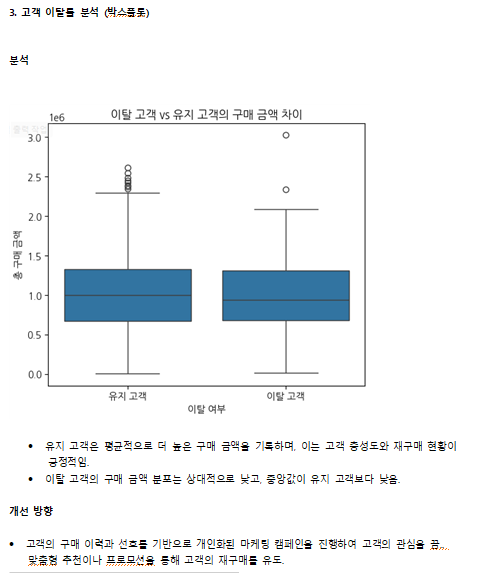
(3) 고객 이탈률 분석 (박스플롯)
plt.figure(figsize=(6, 5))
sns.boxplot(x=df["이탈여부"], y=df["총구매금액"])
plt.xticks([0, 1], ["유지 고객", "이탈 고객"])
plt.title("이탈 고객 vs 유지 고객의 구매 금액 차이")
plt.xlabel("이탈 여부")
plt.ylabel("총 구매 금액")
plt.show()
- 활용 인사이트
- 이탈 고객이 평균적으로 구매액이 낮다면 이탈을 방지하기 위한 리텐션 마케팅이 필요.
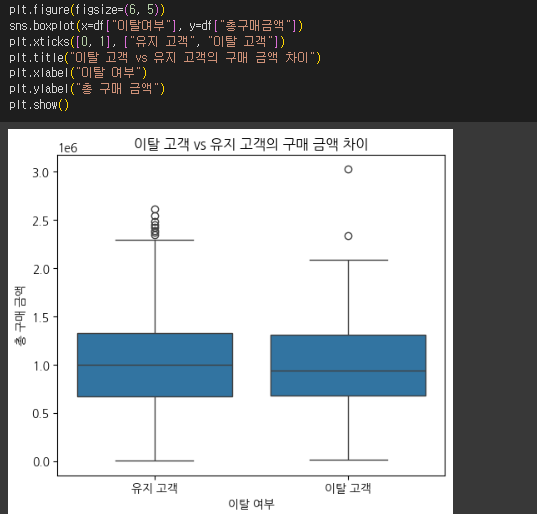
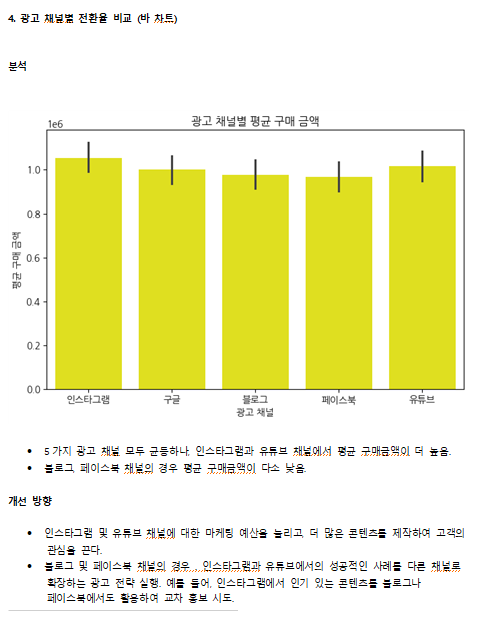
(4) 광고 채널별 전환율 비교 (바 차트)
plt.figure(figsize=(8, 5))
sns.barplot(x=df["광고채널"], y=df["총구매금액"], estimator=np.mean)
plt.title("광고 채널별 평균 구매 금액")
plt.xlabel("광고 채널")
plt.ylabel("평균 구매 금액")
plt.show()
- 활용 인사이트
- 광고 채널 중 전환율이 높은 채널을 집중적으로 활용하여 광고 ROI를 최적화.
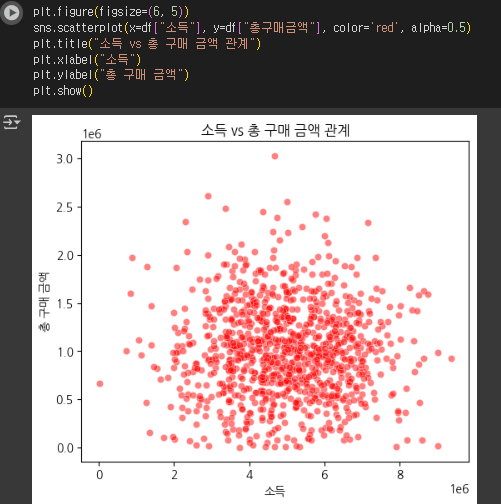
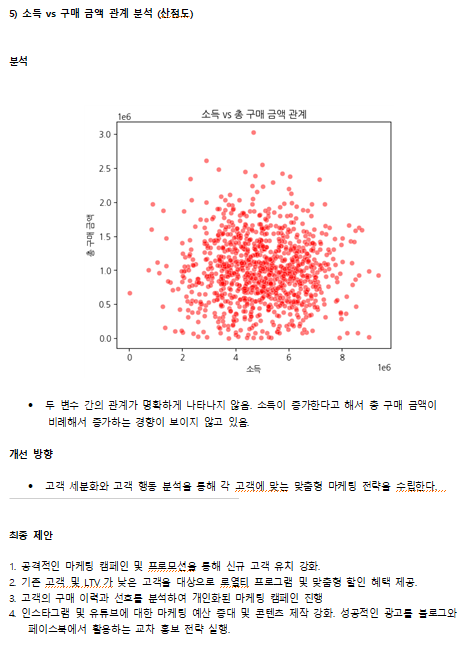
(5) 소득 vs 구매 금액 관계 분석 (산점도)
plt.figure(figsize=(6, 5))
sns.scatterplot(x=df["소득"], y=df["총구매금액"], alpha=0.5)
plt.title("소득 vs 총 구매 금액 관계")
plt.xlabel("소득")
plt.ylabel("총 구매 금액")
plt.show()
- 활용 인사이트
- 소득이 높은 고객이 실제로 더 많이 구매하는지 분석하여 타겟팅 전략을 개선.
(6) 분석을 통한 전략수립
- 신규 고객 유입이 적다면 → 신규 고객 확보를 위한 프로모션 강화.
- LTV가 높은 고객을 찾아 → VIP 고객 대상으로 로열티 프로그램 운영.
- 이탈 고객이 적은 구매액을 보인다면 → 맞춤형 할인 및 재구매 유도 캠페인 진행.
- 광고 채널별 성과를 분석하여 → 효율이 높은 광고 채널에 집중 투자.
- 소득과 구매 금액 간 관계를 분석하여 → 특정 고객층을 타겟팅하는 전략 수립.
(7) 마케팅 보고서 작성
[충성고객 분석을 통한 재구매율 높이기]

3. 데이터 전처리 KPI 분석 종합 실습과제
1) 데이터 전처리 KPI 분석 종합 실습과제 1
📌 실습 개요
한 이커머스 쇼핑몰에서 운영팀이 고객 데이터를 기반으로 그로스 마케팅 KPI를 설정하고 분석하는 데이터 보고서를 작성하려고 합니다.
EDA(탐색적 데이터 분석) 및 데이터 전처리를 수행하여 고객 행동 패턴을 분석하고, 시각화하여 마케팅 전략을 제안하는 것이 목표입니다.
📊 시나리오 및 데이터 설명
✔ 배경:
이커머스 쇼핑몰의 마케팅팀은 최근 고객 유입이 증가했지만, 구매 전환율과 재구매율이 낮은 현상을 발견했습니다.
이에 따라 고객 행동 데이터를 분석하여 마케팅 KPI를 정의하고, 전략을 개선할 방법을 찾고자 합니다.
✔ 목표:
- 신규 고객과 기존 고객의 행동 패턴을 비교하고, 차이를 분석합니다.
- 장바구니 이탈률과 구매 전환율을 분석하여 원인을 찾고 개선 방향을 제안합니다.
- 광고 채널별 성과를 분석하여 ROI가 높은 채널을 식별합니다.
- 재구매율이 높은 고객의 특성을 분석하고, 충성 고객을 유치하는 전략을 제안합니다.
📁 제공 데이터셋 (customer_behavior.csv)
✔ 데이터셋 설명:
1,500명의 고객 데이터를 포함하며, 각 고객의 마케팅 채널, 방문 행동, 구매 패턴, 지출 내역이 포함됩니다.
| 칼럼명 | 설명 |
| 고객ID | 고객 고유 ID |
| 방문횟수 | 최근 6개월 동안 사이트 방문 횟수 |
| 신규고객여부 | 신규 고객(1) 또는 기존 고객(0) |
| 장바구니이탈여부 | 장바구니에 상품을 담았지만 결제하지 않은 경우(1), 결제한 경우(0) |
| 구매횟수 | 해당 고객의 총 구매 횟수 |
| 광고채널 | 고객이 유입된 광고 채널 (구글, 페이스북, 인스타그램, 유튜브, 블로그) |
| 총구매금액 | 고객이 현재까지 쇼핑몰에서 지출한 총 금액 |
| 평균구매주기 | 두 번의 구매 사이 평균 기간 (일 단위) |
| 할인사용여부 | 구매 시 할인 쿠폰 사용 여부 (1=사용, 0=미사용) |
| 재구매여부 | 고객이 2회 이상 구매했으면 1, 아니면 0 |
📝 실습과제
각 실습과제는 그로스 마케팅 KPI 분석과 데이터 전처리를 포함하며, 최종적으로 보고서를 작성하는 형태로 진행됩니다.
🔹 실습과제 1: 데이터 전처리 및 기본 탐색
목표: 데이터셋을 로드하고, 기본적인 전처리를 수행하여 데이터를 정리합니다.
✔ 요구사항:
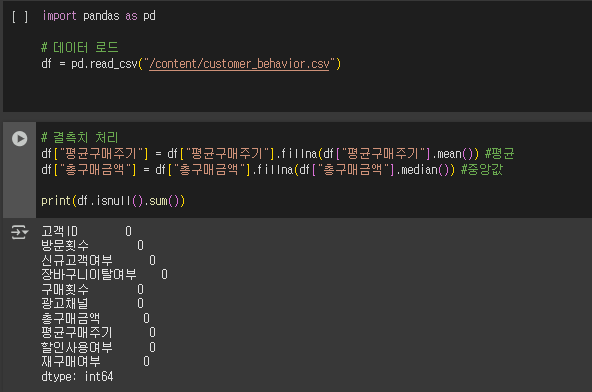
- customer_behavior.csv를 pandas로 로드하세요.
- 결측치가 있는지 확인하고, 다음 방식으로 처리하세요.
- 평균구매주기: 평균값으로 대체
- 총구매금액: 중앙값으로 대체
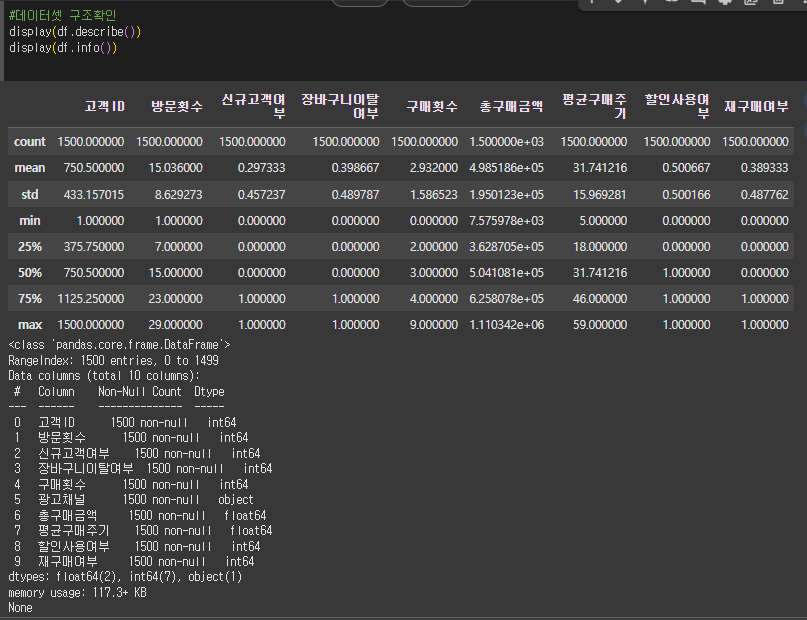
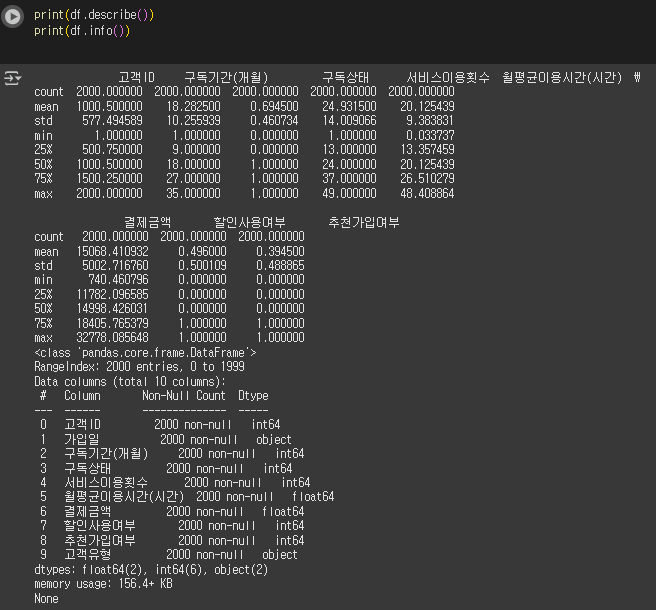
- describe()와 info()를 사용하여 데이터셋의 구조를 확인하세요.
🔹 실습과제 2: 신규 고객 vs 기존 고객 행동 분석
목표: 신규 고객과 기존 고객의 행동 패턴을 비교하여 차이를 분석합니다.
✔ 요구사항:
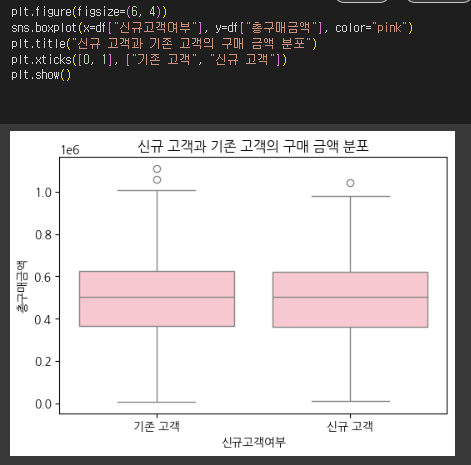
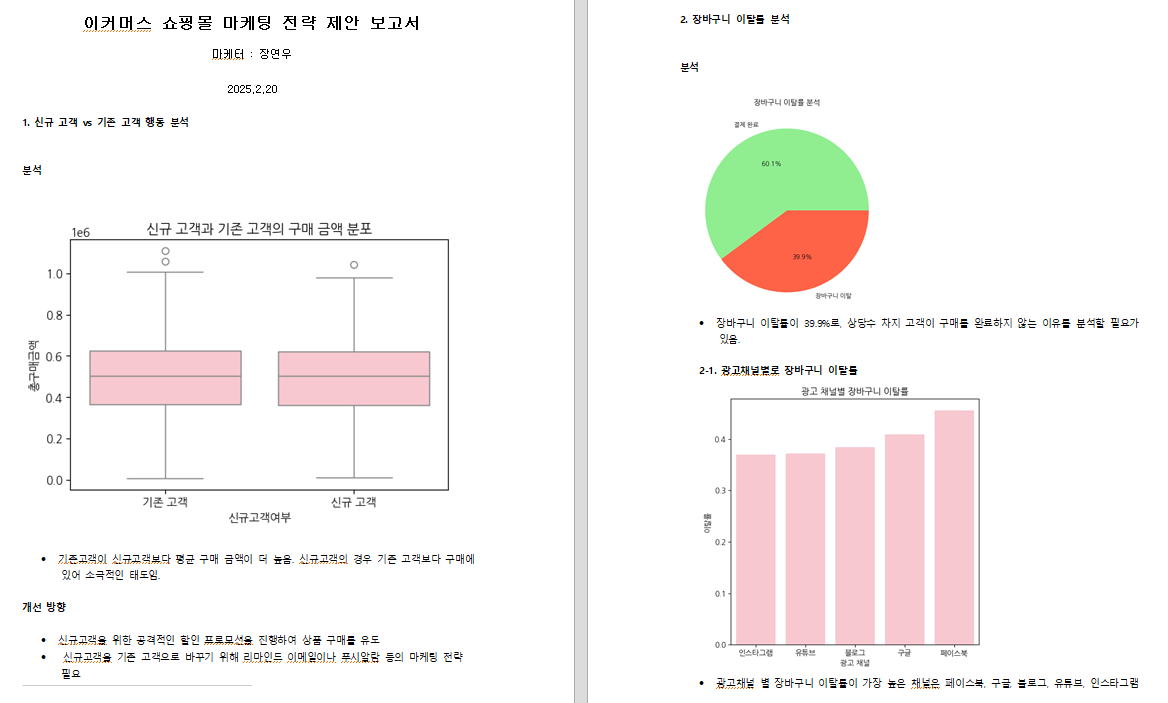
- 신규 고객과 기존 고객의 평균 방문 횟수와 구매 횟수를 비교하세요.
- sns.boxplot()을 사용하여 신규 고객과 기존 고객의 구매 금액 분포를 시각화하세요.
- 신규고객여부별로 평균 구매 금액의 차이가 유의미한지 T-test를 수행하세요.
- 분석 결과를 바탕으로 신규 고객을 유지하기 위한 마케팅 전략을 제안하세요.
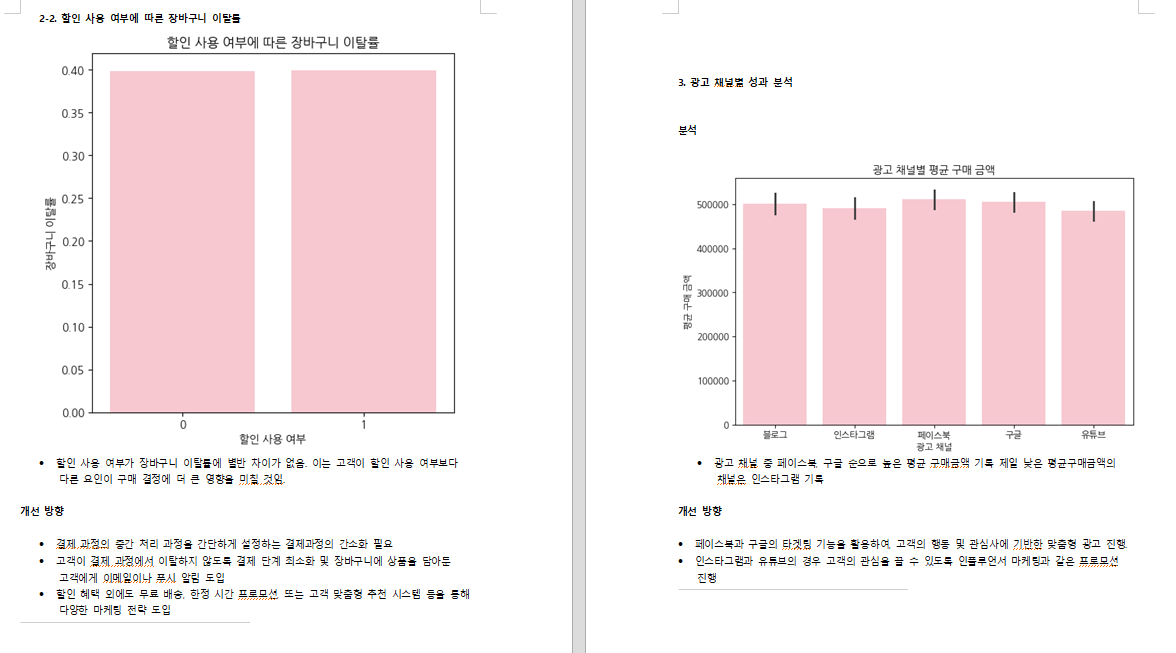
🔹 실습과제 3: 장바구니 이탈률 분석
목표: 장바구니 이탈률을 분석하고, 전환율 개선을 위한 전략을 수립합니다.
✔ 요구사항:
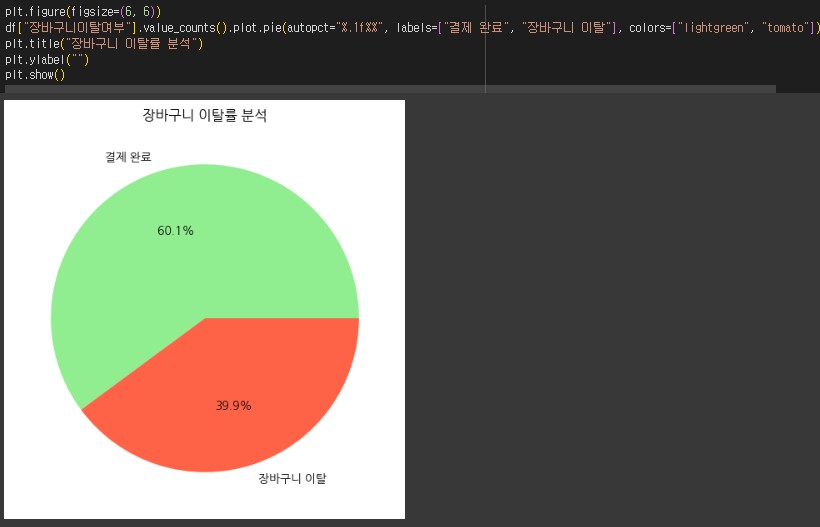
- 장바구니이탈여부가 1인 고객과 0인 고객의 차이를 분석하세요.
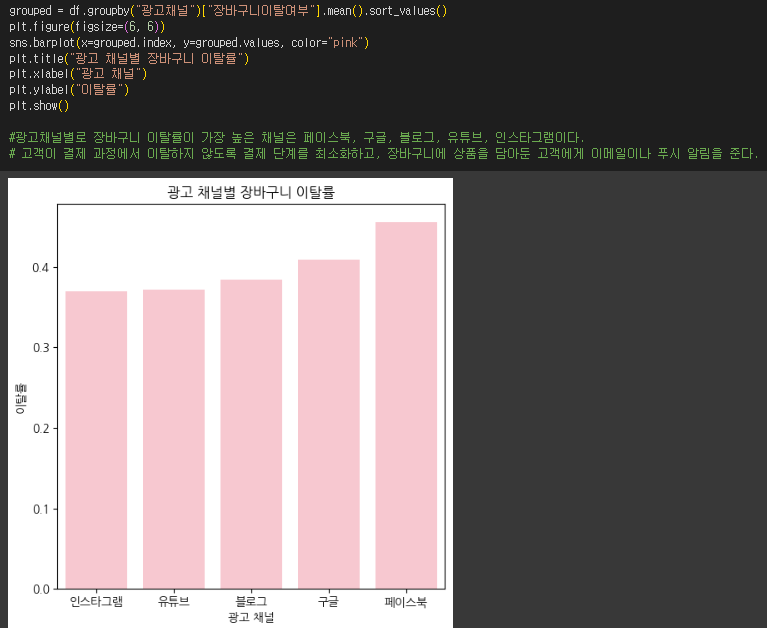
- 광고채널별로 장바구니 이탈률이 가장 높은 채널을 찾아 이탈률 순위표를 작성하세요.
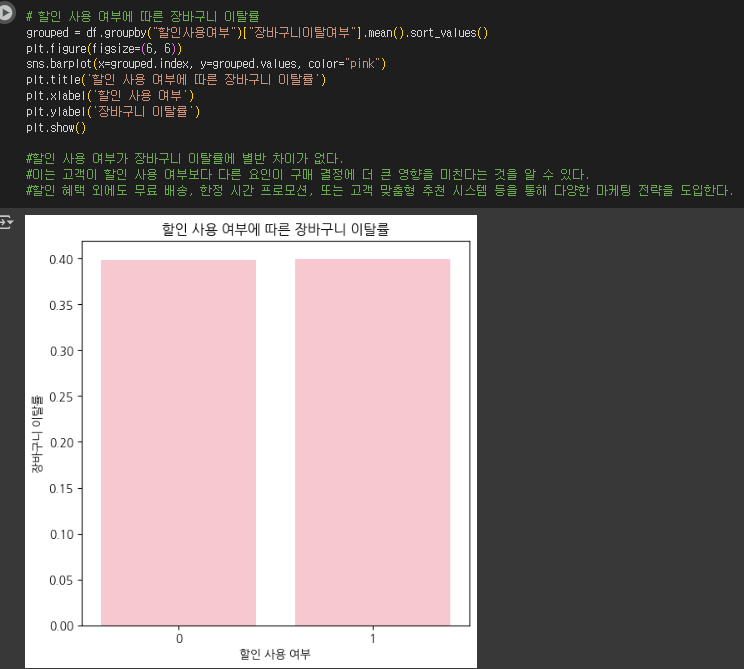
- 할인사용여부가 장바구니 이탈률과 관계가 있는지 확인하고, 바 차트로 시각화하세요.
- 분석 결과를 바탕으로 장바구니 이탈률을 줄이기 위한 제안을 정리하세요.
🔹 실습과제 4: 광고 채널별 성과 분석
목표: 광고 채널별 전환율과 구매 성과를 분석하여 마케팅 예산을 최적화합니다.
✔ 요구사항:
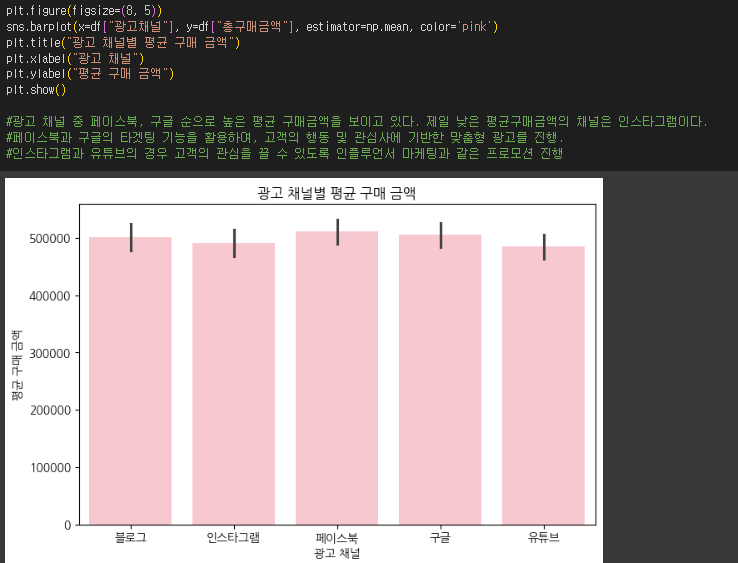
- 광고채널별로 평균 구매 금액과 평균 구매 횟수를 비교하세요.
- sns.barplot()을 사용하여 광고 채널별 평균 구매 금액을 시각화하세요.
- 가장 전환율이 높은 광고 채널을 찾고, ROI를 극대화할 수 있는 마케팅 전략을 제안하세요.
🔹 실습과제 5: 충성 고객 분석 및 재구매율 예측
목표: 충성 고객의 특성을 분석하고, 향후 재구매 가능성이 높은 고객을 예측합니다.
✔ 요구사항:
- 재구매여부가 1인 고객과 0인 고객을 비교하여 재구매율이 높은 고객의 특징을 분석하세요.
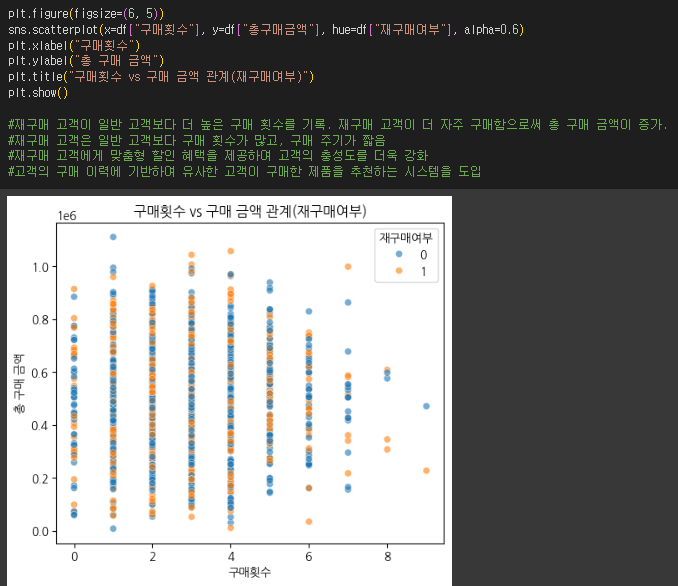
- 구매횟수와 총구매금액이 재구매에 영향을 미치는지 산점도(Scatter Plot)로 시각화하세요.
- 평균구매주기가 짧은 고객이 더 자주 구매하는지 검토하세요.
- 분석 결과를 바탕으로 재구매율을 높이기 위한 고객 리텐션 전략을 제안하세요.
📌 최종 제출물
- 각 실습과제에 대한 코드 및 분석 결과
- 시각화된 그래프
- 결과 요약 및 마케팅 전략 제안
- 실습 과정
- 최종결과

2) 데이터 전처리 KPI 분석 종합 실습과제 2
📌 실습 개요
한 구독 기반 서비스(Subscription Service) 운영팀이 고객 데이터를 기반으로 구독 유지율을 높이기 위한 KPI를 설정하고 분석하는 데이터 보고서를 작성하려고 합니다.
EDA(탐색적 데이터 분석) 및 데이터 전처리를 수행하여 고객 이탈 패턴을 분석하고, 시각화하여 고객 리텐션 전략을 제안하는 것이 목표입니다.
📊 시나리오 및 데이터 설명
✔ 배경
최근 몇 달간 구독 서비스 고객 유지율(Retention Rate)이 하락하고 있으며, 신규 가입자의 이탈률이 증가하고 있습니다.
이에 따라 운영팀은 고객 데이터를 분석하여 구독 이탈 원인을 찾고, 고객 유지 전략을 수립하려 합니다.
✔ 목표
- 구독 유지 고객과 이탈 고객의 차이를 분석하고, 주요 이탈 원인을 식별합니다.
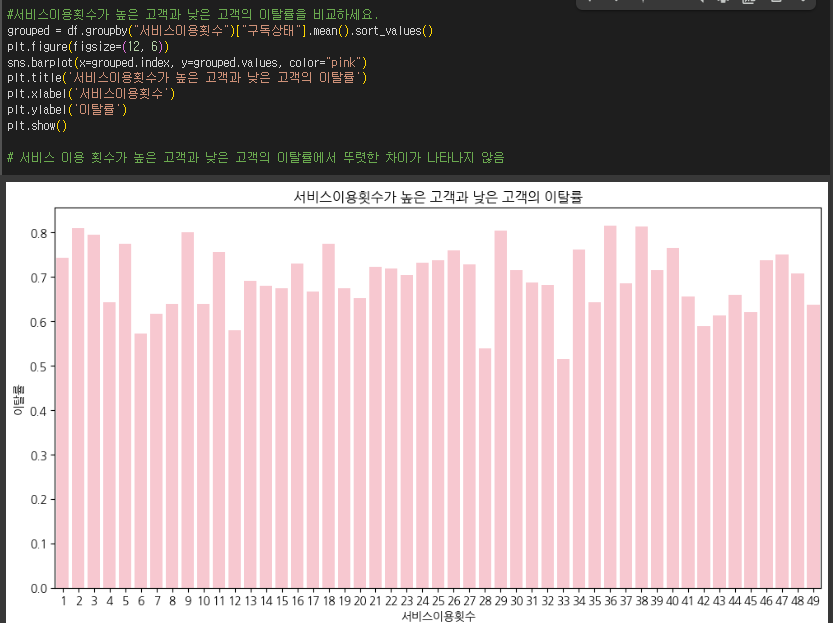
- 서비스 이용 빈도와 이탈률의 관계를 분석하여 구독 유지율을 개선할 방법을 찾습니다.
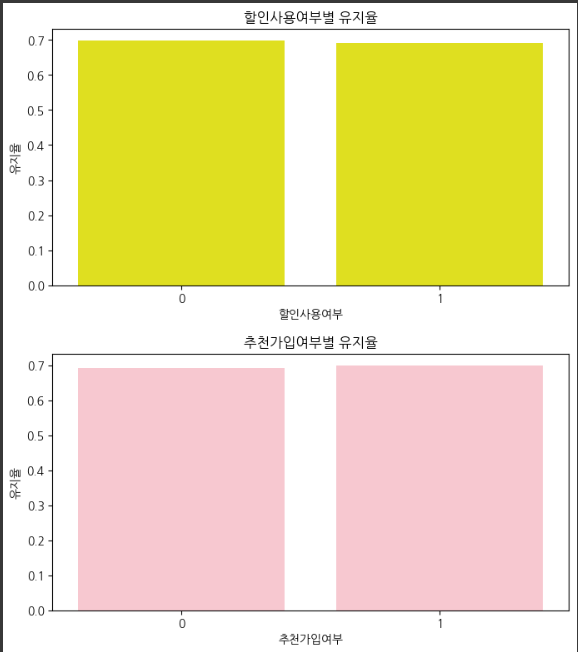
- 프로모션 및 할인 정책이 고객 유지율에 미치는 영향을 분석합니다.
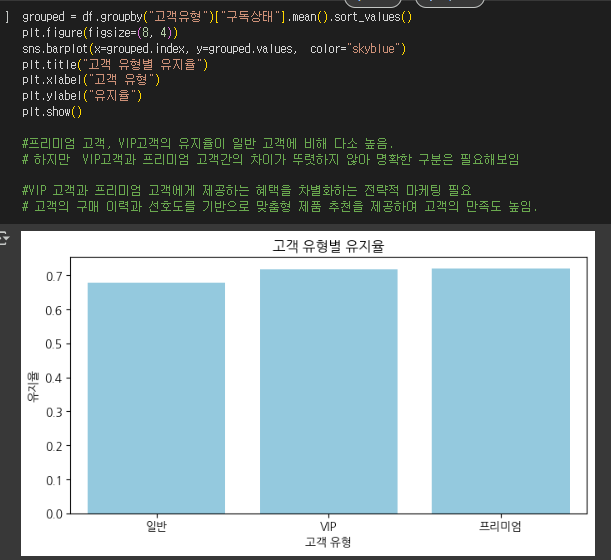
- 고객 유형별 구독 유지 패턴을 분석하고, 개인화된 마케팅 전략을 제안합니다.
📁 제공 데이터셋 (subscription_data.csv)
✔ 데이터셋 설명
총 2,000명의 구독 고객 데이터를 포함하며, 각 고객의 구독 상태, 서비스 이용 패턴, 프로모션 참여 여부 등의 정보를 포함합니다.
| 컬럼명 | 설명 |
| 고객ID | 고객 고유 ID |
| 가입일 | 서비스 가입 날짜 |
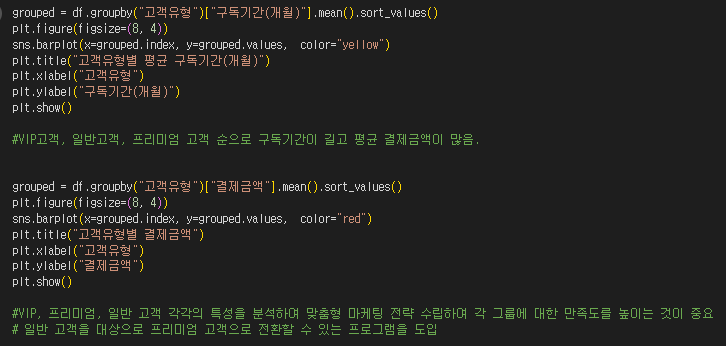
| 구독기간(개월) | 해당 고객이 서비스를 유지한 개월 수 |
| 구독상태 | 현재 구독 유지(1) 또는 이탈(0) 여부 |
| 서비스이용횟수 | 최근 6개월 동안의 서비스 이용 횟수 |
| 월평균이용시간(시간) | 고객이 월평균 사용한 시간 |
| 결제금액 | 월 결제 금액 |
| 할인사용여부 | 할인 또는 프로모션 적용 여부 (1=적용, 0=미적용) |
| 추천가입여부 | 추천인 링크를 통해 가입했으면 1, 아니면 0 |
| 고객유형 | 고객 유형 (일반, 프리미엄, VIP) |
📌 최종 제출물
- 각 실습과제에 대한 코드 및 분석 결과
- 시각화된 그래프
- 결과 요약 및 구독 유지 전략 제안
- 실습과정


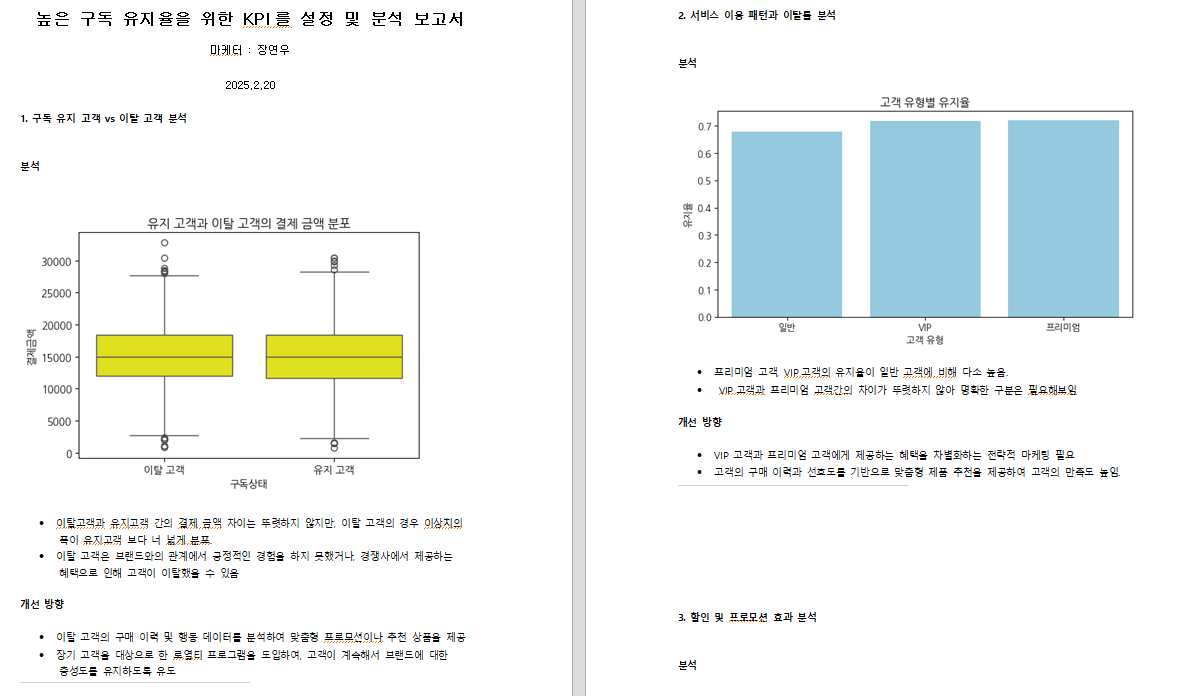
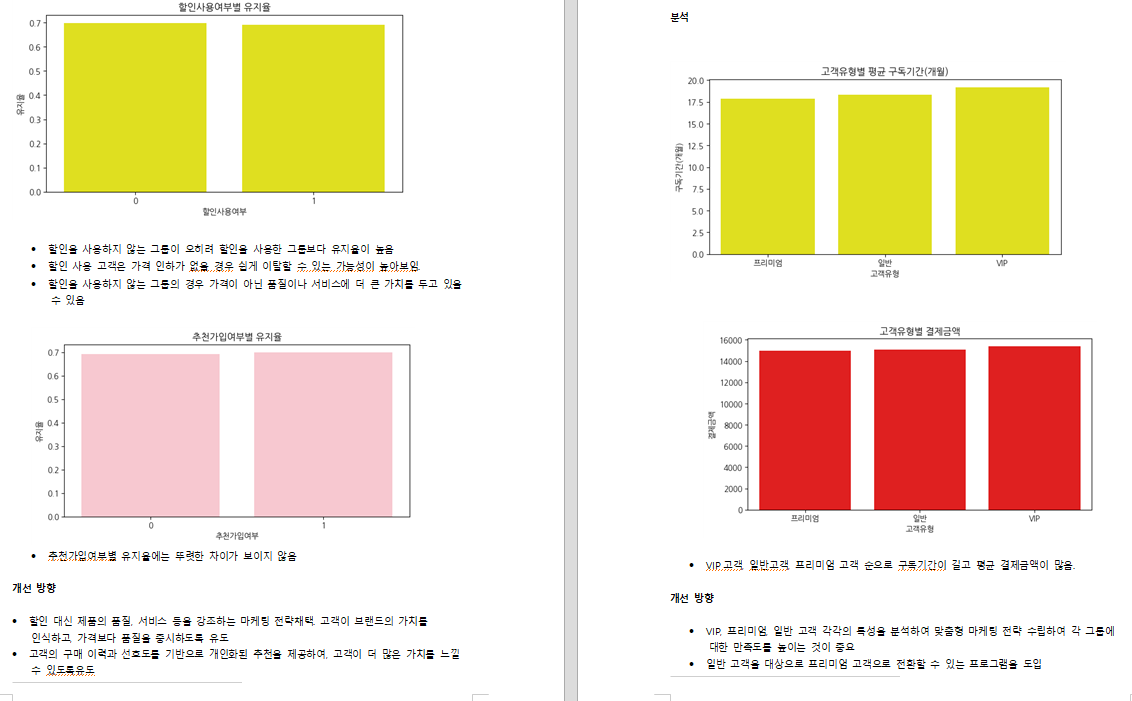
- 최종결과

'⚠️그로스마케터 성장 보고합니다⚠️' 카테고리의 다른 글
| GM. 통계분석 기초2 (상관관계, 상관분석, 마케팅 데이터의 주요 지표 분석, 고객 세분화) (1) | 2025.03.09 |
|---|---|
| GM. 통계분석 기초1 (통계, 데이터 분포와 확률, 회귀분석, 단순회귀, 다중회귀) (0) | 2025.03.08 |
| GM. 데이터수집 및 전처리2 (설문조사를 통한 데이터 수집, Matplotlib에 의한 시각화, 외부 데이터셋, 데이터 정제, 결측치, 표준화, 정규화) (0) | 2025.03.04 |
| GM. 데이터수집 및 전처리1 (웹 크롤링, API, API 데이터 수집, 마케팅 보고서만들기) (7) | 2025.03.03 |
| GM. 데이터분석 개론 정리4 (JOIN, UNION, 고급 SQL-집계 함수와 그룹화, Python과 SQL 연동) (0) | 2025.03.03 |



