
설문조사를 통한 데이터 수집
1. 개요
(1) 설문조사의 목적
설문조사는 그로스마케팅에서 다음과 같은 목적을 가질 수 있습니다.
- 고객 페르소나 구축: 고객의 연령, 성별, 직업, 관심사 등 파악
- 제품/서비스 만족도 조사: 고객이 제품을 어떻게 평가하는지 조사
- 광고/캠페인 효과 분석: 특정 광고나 마케팅 캠페인이 효과가 있었는지 평가
- 구매 의사결정 과정 분석: 고객이 제품을 구매하기까지 어떤 요인이 영향을 미쳤는지 확인
- NPS(Net Promoter Score) 분석: 고객의 브랜드 추천 의향 평가
2. 설문 설계 예제: 그로스마케팅 캠페인 효과 분석
(1) 설문 대상
최근 3개월 내 브랜드의 제품을 구매했거나, 마케팅 캠페인을 접한 고객
(2) 설문 질문 설계
설문지는 폐쇄형 질문(객관식)과 개방형 질문(주관식)을 혼합하여 구성할 수 있다.
[기본 정보]
- 연령대는 어떻게 되십니까?
- ① 10대 ② 20대 ③ 30대 ④ 40대 ⑤ 50대 이상
- 성별을 선택해 주세요.
- ① 남성 ② 여성 ③ 기타
- 현재 직업을 선택해 주세요.
- ① 학생 ② 직장인 ③ 자영업자 ④ 기타
[마케팅 캠페인 경험]
- 최근 3개월 내 당사의 광고(유튜브, 인스타그램, 페이스북, 블로그 등)를 보신 적이 있습니까?
- ① 예 ② 아니오
- 해당 광고를 접한 후 제품을 구매하셨습니까?
- ① 예 ② 아니오
- 어떤 채널에서 광고를 접하셨습니까? (중복 선택 가능)
- ① 유튜브 ② 인스타그램 ③ 페이스북 ④ 네이버 블로그 ⑤ 기타
- 해당 광고가 구매 결정에 얼마나 영향을 미쳤습니까? (1점: 전혀 영향 없음 ~ 5점: 매우 영향 큼)
- ① 1 ② 2 ③ 3 ④ 4 ⑤ 5
[브랜드 만족도 조사]
- 제품 또는 서비스에 대한 전반적인 만족도를 평가해 주세요.
- ① 매우 불만족 ② 불만족 ③ 보통 ④ 만족 ⑤ 매우 만족
- 제품을 다시 구매하거나 추천할 의향이 있습니까?
- ① 예 ② 아니오
- 개선이 필요한 부분이 있다면 자유롭게 작성해 주세요.
- (주관식 응답)
3. 설문 결과 분석
아래는 설문조사 데이터를 분석하는 코드이다. 그래프 없이 데이터의 통계를 확인하고, 주요 패턴을 파악할 수 있도록 작성되었다.
import pandas as pd
# 예제 설문 데이터 생성
data = {
"연령대": ["20대", "30대", "40대", "20대", "50대"],
"성별": ["남성", "여성", "여성", "남성", "남성"],
"광고_시청": ["예", "예", "아니오", "예", "예"],
"광고_채널": ["유튜브", "인스타그램", "없음", "페이스북", "네이버 블로그"],
"광고_영향": [5, 4, 0, 3, 2],
"제품_만족도": [4, 5, 3, 5, 2],
"재구매_의향": ["예", "예", "아니오", "예", "아니오"]
}
df = pd.DataFrame(data)
# 광고 시청 여부별 응답자 수 확인
ad_view_counts = df["광고_시청"].value_counts()
print("광고 시청 여부 분포:\\n", ad_view_counts)
# 광고 채널별 응답자 수 확인
ad_channel_counts = df["광고_채널"].value_counts()
print("\\n광고 채널별 분포:\\n", ad_channel_counts)
# 제품 만족도 평균 값 계산
avg_satisfaction = df["제품_만족도"].mean()
print("\\n제품 만족도 평균 값:", avg_satisfaction)
# 광고 영향도와 제품 만족도의 상관관계 확인
correlation = df[["광고_영향", "제품_만족도"]].corr()
print("\\n광고 영향도와 제품 만족도의 상관관계:\\n", correlation)
# 연령대별 광고 시청 여부 확인
age_ad_view = df.groupby("연령대")["광고_시청"].value_counts()
print("\\n연령대별 광고 시청 여부:\\n", age_ad_view)
# 재구매 의향 비율 계산
repurchase_rate = df["재구매_의향"].value_counts(normalize=True) * 100
print("\\n재구매 의향 비율(%):\\n", repurchase_rate)
# 광고 영향도 평균값
avg_ad_influence = df["광고_영향"].mean()
print("\\n광고 영향도 평균 값:", avg_ad_influence)


Matplotlib에 의한 시각화
1. Matplotlib 개요
- Matplotlib은 Python에서 데이터를 시각화할 때 사용하는 강력한 라이브러리이다.
- 특히 pyplot 모듈을 사용하여 다양한 그래프(선 그래프, 바 그래프, 히스토그램 등)를 손쉽게 생성할 수 있다.
- 주요 기능
- 선 그래프 (Line Plot)
- 바 그래프 (Bar Chart)
- 히스토그램 (Histogram)
- 산점도 (Scatter Plot)
- 박스 플롯 (Box Plot)
- 서브플롯 (Subplot) 등
- Matplotlib 설치 명령어
pip install matplotlib
2. Matplotlib 함수별 상세 설명 및 사용 방법
1) 선 그래프 (Line Plot) - plt.plot()
- 설명: plt.plot() 함수는 선 그래프(Line Plot)를 그릴 때 사용.
- 사용법:
plt.plot(x, y, marker='o', linestyle='-', color='b', label='Data')
- 사용 예제
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [10, 20, 25, 30, 50]
plt.plot(x, y, marker='o', linestyle='-', color='b', label="Line Data")
plt.title("Line Graph Example")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
plt.legend() # 범례 추가
plt.grid(True) # 격자 추가
plt.show()
- 주요 매개변수
- x, y: X축, Y축 데이터
- marker: 점 모양 ('o', '*', 's', 'D', 'x' 등)
- linestyle: 선 스타일 ('-' 실선, '--' 점선, ':' 점선, '-.' 점-대시)
- color: 선 색상 ('r', 'g', 'b', '#FF5733' 등)
- label: 범례 추가


2) 바 그래프 (Bar Chart) - plt.bar()
- 설명: plt.bar() 함수는 막대 그래프(Bar Chart)를 그릴 때 사용.
- 사용법:
plt.bar(categories, values, color=['red', 'blue', 'green'])
- 주요 매개변수
- categories: X축 레이블
- values: Y축 값
- color: 각 막대의 색상 지정
- width: 막대의 너비 조정 (기본값 0.8)
- 사용 예제
import matplotlib.pyplot as plt
categories = ["A", "B", "C", "D"]
values = [10, 25, 15, 30]
plt.bar(categories, values, color=['red', 'blue', 'green', 'purple'])
plt.title("Bar Chart Example")
plt.xlabel("Categories")
plt.ylabel("Values")
plt.show()


3) 히스토그램 (Histogram) - plt.hist()
- 설명: plt.hist() 함수는 히스토그램(Histogram)을 그릴 때 사용.
- 사용법:
plt.hist(data, bins=30, color='blue', edgecolor='black')
- 주요 매개변수
- data: 히스토그램을 만들 데이터
- bins: 막대의 개수 (구간 개수)
- color: 막대 색상
- edgecolor: 막대 테두리 색상
- 사용 예제
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000) # 평균 0, 표준편차 1인 정규분포 데이터 생성
plt.hist(data, bins=30, color='skyblue', edgecolor='black')
plt.title("Histogram Example")
plt.xlabel("Value")
plt.ylabel("Frequency")
plt.show()


4) 산점도 (Scatter Plot) - plt.scatter()
- 설명: plt.scatter() 함수는 산점도(Scatter Plot)를 그릴 때 사용.
- 사용법:
plt.scatter(x, y, color='r', marker='o')
- 주요 매개변수
- x, y: X축, Y축 데이터
- color: 점 색상
- marker: 점 모양 ('o', '*', 's', 'D', 'x' 등)
- s: 점 크기
- 사용 예제
import matplotlib.pyplot as plt
import numpy as np
x = np.random.rand(50)
y = np.random.rand(50)
plt.scatter(x, y, color='red', marker='o')
plt.title("Scatter Plot Example")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
plt.show()


5) 원형 그래프(Pie Chart) - plt.pie()
- 설명: plt.pie() 함수는 원형 그래프(Pie Chart)를 그릴 때 사용.
- 사용법:
plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=['red', 'blue'])
- 주요 매개변수
- sizes: 각 조각의 크기
- labels: 각 조각의 레이블
- autopct: 퍼센트 표시 형식 ('%1.1f%%' -> 소수점 1자리까지 표시)
- colors: 색상 지정
- startangle: 그래프 시작 각도 (기본 0)
- 사용 예제
import matplotlib.pyplot as plt
sizes = [30, 20, 50]
labels = ["A", "B", "C"]
colors = ['red', 'blue', 'green']
plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors, startangle=90)
plt.title("Pie Chart Example")
plt.show()

6) 여러 개의 그래프 표시 (Subplot) - plt.subplot()
- 설명: plt.subplot() 함수는 여러 개의 그래프를 한 화면에 표시할 때 사용.
- 사용법:
plt.subplot(rows, cols, index)
- 주요 매개변수
- rows: 행 개수
- cols: 열 개수
- index: 현재 그래프 위치
- 사용 예제
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1) # 1행 2열 중 첫 번째
plt.plot(x, y1, color='blue')
plt.title("Sine Wave")
plt.subplot(1, 2, 2) # 1행 2열 중 두 번째
plt.plot(x, y2, color='red')
plt.title("Cosine Wave")
plt.tight_layout() # 간격 자동 조정
plt.show()

7) 박스 플롯(Box Plot) - plt.boxplot()
- 설명: plt.boxplot() 함수는 박스 플롯(Box Plot, 상자 그림)을 그릴 때 사용.
- 사용법:
plt.boxplot(data)
- 주요 매개변수
- data: 입력 데이터
- vert: 세로(True) 또는 가로(False) 방향 선택
- patch_artist: 박스를 색칠할지 여부 (True)
- 사용 예제
import matplotlib.pyplot as plt
import numpy as np
data = [np.random.randn(100), np.random.randn(100) + 1, np.random.randn(100) + 2]
plt.boxplot(data, patch_artist=True, vert=True)
plt.title("Box Plot Example")
plt.xlabel("Categories")
plt.ylabel("Values")
plt.show()

8) 추가적인 유용한 함수
| 함수 | 설명 |
| plt.title("제목") | 그래프 제목 추가 |
| plt.xlabel("X축 이름") | X축 이름 추가 |
| plt.ylabel("Y축 이름") | Y축 이름 추가 |
| plt.grid(True) | 그래프에 격자 추가 |
| plt.legend() | 범례 추가 |
| plt.figure(figsize=(w, h)) | 그래프 크기 조절 |
| plt.xlim(min, max) | X축 범위 설정 |
| plt.ylim(min, max) | Y축 범위 설정 |
3. 그래프 사용 목적
| 그래프 종류 | 활용 사례 | 주요 목적 |
| 히스토그램 | 광고 클릭 수 분포 분석 | 데이터의 분포 파악 |
| 선형 그래프 | 시간에 따른 매출 변화 | 시간별 트렌드 분석 |
| 막대 그래프 | 채널별 전환율 비교 | 범주형 데이터 비교 |
| 산점도 | 광고비 vs 전환율 관계 분석 | 상관관계 분석 |
| 파이 차트 | 고객 세그먼트 비율 분석 | 비율 비교 |
| 박스 플롯 | 이상치가 포함된 수익 분석 | 이상치 감지 및 데이터 분포 확인 |
| 히트맵 | 시간대별 광고 성과 분석 | 다차원 데이터의 패턴 분석 |
4. 설문조사 데이터 분석 활용
1) 광고 채널별 효과 분석
- 어떤 광고 채널(유튜브, 인스타그램, 페이스북 등)이 가장 많은 고객에게 도달했는지 분석
- 광고 시청 후 구매 전환율이 높은 채널 확인
2) 연령대별 광고 반응 분석
- 특정 연령층이 특정 광고 채널에 더 반응하는지 분석
- 연령대별 선호도를 반영한 맞춤형 마케팅 전략 수립
3) NPS 분석을 통한 고객 추천 의향
- 제품 만족도가 높은 고객과 낮은 고객의 특성을 비교하여 개선 방향 도출
- 추천 의향이 높은 고객을 대상으로 리워드 프로그램 기획
설문조사와 외부 데이터셋 활용
1. 외부 데이터셋 활용 목적
1) 설문 데이터 한계를 보완
- 설문조사는 일반적으로 표본 크기가 제한됨 → 외부 데이터로 보완 가능
- 응답자의 자기보고(Self-report) 편향 가능성 존재 → 객관적 데이터로 교차 검증
2) 설문 데이터와 시장 데이터 결합
- 예: 설문을 통해 특정 제품의 인지도를 조사하면서, 외부 데이터셋(구글 트렌드, SNS 데이터 등)을 활용해 시장 내 관심도를 비교
3) 공공 데이터 및 통계 활용
- 설문 응답자의 소비 성향을 분석하면서, 통계청 또는 신용카드 소비 데이터 활용 가능
4) 고객 행동 데이터 연계
- 설문 응답자들이 실제로 어떤 구매 패턴을 보이는지 매출 데이터와 비교
2. 외부 데이터셋 활용 예제: 그로스마케팅 분석
(1) 데이터 설명
- 설문조사 데이터: 고객들의 광고 인식 및 제품 만족도
- 외부 데이터: 구글 트렌드 검색량, SNS 언급량, 온라인 판매량
(2) 예제 코드: 설문조사 데이터 + 외부 데이터 활용
import pandas as pd
# 설문조사 데이터 (고객 만족도 및 광고 효과 조사)
survey_data = pd.DataFrame({
"연령대": ["20대", "30대", "40대", "20대", "50대"],
"성별": ["남성", "여성", "여성", "남성", "남성"],
"광고_시청": ["예", "예", "아니오", "예", "예"],
"광고_채널": ["유튜브", "인스타그램", "없음", "페이스북", "네이버 블로그"],
"광고_영향": [5, 4, 0, 3, 2],
"제품_만족도": [4, 5, 3, 5, 2],
"재구매_의향": ["예", "예", "아니오", "예", "아니오"]
})
# 외부 데이터: 해당 브랜드의 월별 검색량 및 SNS 언급량
external_data = pd.DataFrame({
"월": ["1월", "2월", "3월", "4월", "5월"],
"구글_트렌드_검색량": [1200, 1500, 1800, 1700, 1600],
"SNS_언급량": [300, 350, 500, 450, 400],
"온라인_판매량": [100, 150, 200, 180, 160]
})
# 데이터 출력
print("설문조사 데이터:\\n", survey_data)
print("\\n외부 데이터:\\n", external_data)
# 데이터 결합 (예: 3월 설문조사와 3월 검색량 비교)
merged_data = survey_data.assign(
구글_트렌드_검색량=external_data.loc[2, "구글_트렌드_검색량"],
SNS_언급량=external_data.loc[2, "SNS_언급량"],
온라인_판매량=external_data.loc[2, "온라인_판매량"]
)
print("\\n설문 데이터 + 외부 데이터 결합:\\n", merged_data)


- Seaborn
- Python에서 데이터 시각화를 위한 라이브러리로, Matplotlib을 기반으로 만들어졌다.
- 분포 그래프, 회귀선 그래프 등 통계 분석에 자주 사용되는 시각화 기능을 제공한다.
- Seaborn 설치 방법
pip install seaborn
- 시각화
import matplotlib.pyplot as plt import koreanize_matplotlib # 한글 폰트 적용 import seaborn as sns # 스타일 설정 sns.set(style="whitegrid") # 1. 설문조사 데이터 시각화 # 1-1. 광고 시청 여부별 응답자 수 plt.figure(figsize=(6, 4)) sns.countplot(x="광고_시청", data=survey_data, palette="Set2") plt.title("광고 시청 여부별 응답자 수") plt.xlabel("광고 시청 여부") plt.ylabel("응답자 수") plt.show() # 1-2. 광고 채널별 응답자 수 plt.figure(figsize=(8, 4)) sns.countplot(x="광고_채널", data=survey_data, palette="Set3", order=survey_data["광고_채널"].value_counts().index) plt.title("광고 채널별 응답자 수") plt.xlabel("광고 채널") plt.ylabel("응답자 수") plt.xticks(rotation=45) plt.show() # 1-3. 제품 만족도 분포 plt.figure(figsize=(6, 4)) sns.histplot(survey_data["제품_만족도"], bins=5, kde=True, color="skyblue") plt.title("제품 만족도 분포") plt.xlabel("제품 만족도") plt.ylabel("빈도") plt.show() # 1-4. 광고 영향도와 제품 만족도의 산점도 plt.figure(figsize=(6, 4)) sns.scatterplot(x="광고_영향", y="제품_만족도", data=survey_data, hue="성별", palette="Set1") plt.title("광고 영향도와 제품 만족도의 관계") plt.xlabel("광고 영향도") plt.ylabel("제품 만족도") plt.show() # 1-5. 연령대별 광고 시청 여부 plt.figure(figsize=(8, 4)) sns.countplot(x="연령대", hue="광고_시청", data=survey_data, palette="Set2") plt.title("연령대별 광고 시청 여부") plt.xlabel("연령대") plt.ylabel("응답자 수") plt.show() # 1-6. 재구매 의향 비율 plt.figure(figsize=(6, 4)) survey_data["재구매_의향"].value_counts(normalize=True).plot.pie(autopct='%1.1f%%', colors=["lightgreen", "lightcoral"]) plt.title("재구매 의향 비율") plt.ylabel("") plt.show() # 2. 외부 데이터 시각화 # 2-1. 월별 구글 트렌드 검색량 plt.figure(figsize=(8, 4)) sns.lineplot(x="월", y="구글_트렌드_검색량", data=external_data, marker="o", color="blue") plt.title("월별 구글 트렌드 검색량") plt.xlabel("월") plt.ylabel("검색량") plt.show() # 2-2. 월별 SNS 언급량 plt.figure(figsize=(8, 4)) sns.lineplot(x="월", y="SNS_언급량", data=external_data, marker="o", color="green") plt.title("월별 SNS 언급량") plt.xlabel("월") plt.ylabel("SNS 언급량") plt.show() # 2-3. 월별 온라인 판매량 plt.figure(figsize=(8, 4)) sns.lineplot(x="월", y="온라인_판매량", data=external_data, marker="o", color="red") plt.title("월별 온라인 판매량") plt.xlabel("월") plt.ylabel("온라인 판매량") plt.show() # 3. 결합 데이터 시각화 # 3-1. 광고 영향도와 온라인 판매량의 관계 plt.figure(figsize=(6, 4)) sns.scatterplot(x="광고_영향", y="온라인_판매량", data=merged_data, hue="성별", palette="Set1") plt.title("광고 영향도와 온라인 판매량의 관계") plt.xlabel("광고 영향도") plt.ylabel("온라인 판매량") plt.show() # 3-2. 제품 만족도와 온라인 판매량의 관계 plt.figure(figsize=(6, 4)) sns.scatterplot(x="제품_만족도", y="온라인_판매량", data=merged_data, hue="성별", palette="Set2") plt.title("제품 만족도와 온라인 판매량의 관계") plt.xlabel("제품 만족도") plt.ylabel("온라인 판매량") plt.show() 

- 한글 안나올 때
- !pip install koreanize_matplotlib 설치 후
import koreanize_matplotlib
- !pip install koreanize_matplotlib 설치 후
데이터 변환 및 결측치 처리
1. 데이터 변환의 중요성
1) 데이터 변환이 필요한 이유
- 데이터 정제(Data Cleaning): 결측값, 이상치를 처리하여 신뢰성 있는 데이터 확보
- 데이터 표준화(Standardization): 분석 및 비교를 위해 일관된 데이터 형식 유지
- 특성 엔지니어링(Feature Engineering): 마케팅 인사이트를 도출하기 위한 새로운 변수 생성
- 머신러닝 모델 준비(Model Preparation): 모델 학습을 위한 데이터 전처리 수행
2) API 통신 중 발생할 수 있는 결측치와 데이터베이스 저장 형태
- NULL 값으로 저장되는 경우
- API에서 특정 필드가 제공되지 않거나 응답 값이 null로 설정되어 있는 경우, 데이터베이스의 해당 필드에 NULL 값이 저장될 수 있다.
- 빈 문자열로 저장되는 경우
- API에서 데이터가 null이 아닌 빈 문자열로 제공되면, 데이터베이스에 그대로 빈 문자열("")이 저장될 수 있다.
- 0 또는 기본값으로 저장되는 경우
- 일부 API는 값이 없는 경우 null이 아니라 0 또는 특정 기본값을 반환할 수 있다. 이 경우 데이터베이스에도 해당 값이 저장된다.
- 데이터 타입이 잘못 저장되는 경우
- API가 비정상적인 데이터 형식(예: 숫자 필드에 문자열 값)을 반환하는 경우, 데이터베이스에 저장할 때 오류가 발생하거나 예상치 못한 값이 저장될 수 있다.
- 특정 데이터가 아예 저장되지 않는 경우
- API 응답에서 필드 자체가 누락되면, 데이터베이스에 해당 필드가 아예 저장되지 않거나, 기본값이나 NULL로 저장될 수 있다.
2. 데이터 변환 기법
1) 데이터 정제 (Data Cleaning)
- 그로스 마케팅 데이터를 분석하기 전에 결측값과 이상치를 처리해야 한다.
- 결측값이 있으면 평균값 또는 중앙값으로 대체
- 이상치(극단값)는 제거하거나 다른 값으로 조정(fillna가 결측값을 찾아낸다)
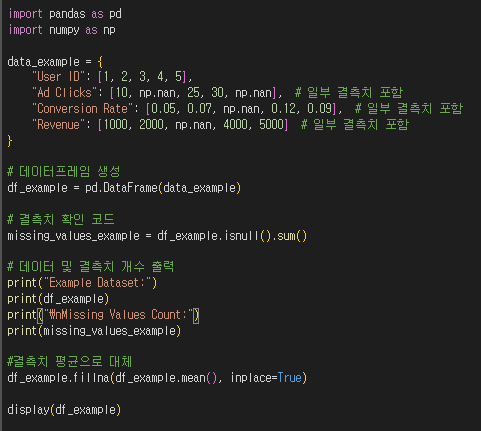
- 결측치 확인 : isnull() 함수는 데이터프레임 또는 시리즈에서 결측치(NaN)를 확인하는 함수이다.
결과는 각 값이 결측치인지(True) 또는 아닌지(False)를 나타내는 불리언(Boolean) 값으로 반환된다.import pandas as pd import numpy as np data_example = { "User ID": [1, 2, 3, 4, 5], "Ad Clicks": [10, np.nan, 25, 30, np.nan], # 일부 결측치 포함 "Conversion Rate": [0.05, 0.07, np.nan, 0.12, 0.09], # 일부 결측치 포함 "Revenue": [1000, 2000, np.nan, 4000, 5000] # 일부 결측치 포함 } # 데이터프레임 생성 df_example = pd.DataFrame(data_example) # 결측치 확인 코드 missing_values_example = df_example.isnull().sum() # 데이터 및 결측치 개수 출력 print("Example Dataset:") print(df_example) print("\\nMissing Values Count:") print(missing_values_example) df_example.fillna(df_example.mean(), inplace=True) display(df_example)

2) 데이터 타입 변환 (Data Type Conversion)
- 그로스 마케팅 데이터를 분석할 때는 데이터 유형을 적절하게 변환해야 한다.
- 문자열을 숫자로 변환 (예: "Yes"/"No" → 1/0)
- 날짜 데이터를 변환하여 분석 가능하도록 변경
# 광고 시청 여부를 0과 1로 변환
df["Ad Viewed"] = ["Yes", "No", "Yes", "No", "Yes"]
df["Ad Viewed"] = df["Ad Viewed"].map({"Yes": 1, "No": 0})
# 날짜 데이터 변환
df["Survey Date"] = pd.to_datetime(["2024-02-01", "2024-02-02", "2024-02-03", "2024-02-04", "2024-02-05"])
print(df["Ad Viewed"])
print(df)
3) 범주형 데이터 변환 (Categorical Encoding)
- 광고 캠페인이나 고객 세그먼트 같은 범주형 데이터는 머신러닝 모델에서 바로 사용할 수 없기 때문에 숫자로 변환해야 한다.
- 레이블 인코딩(Label Encoding): 범주형 데이터를 숫자로 변환
- 원-핫 인코딩(One-Hot Encoding): 범주형 데이터를 여러 개의 이진(0/1) 컬럼으로 변환
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
# 예제 데이터 생성 (결측값 포함)
data = {
"User ID": [101, 102, 103, 104, 105],
"Age": [25, 30, np.nan, 40, 35], # 결측값 포함
"Ad Clicks": [10, 50, 35, 30, 60],
"Conversion Rate": [0.02, 0.05, 0.03, 0.04, 0.07],
"Ad Influence": [5, np.nan, 3, 4, 5], # 결측값 포함
"Product Satisfaction": [np.nan, 4, 3, 5, 4], # 결측값 포함
"Campaign": ["YouTube Ad", "SNS Ad", "Search Ad", "Email Marketing", "SNS Ad"]
}
df = pd.DataFrame(data)
# 결측값을 각 컬럼의 평균으로 대체
df.fillna(df.mean(numeric_only=True), inplace=True)
# 레이블 인코딩 (Campaign을 숫자로 변환)
le = LabelEncoder()
df["Campaign_Encoded"] = le.fit_transform(df["Campaign"])
# 원-핫 인코딩 적용
df_one_hot = pd.get_dummies(df, columns=["Campaign"])
# 최종 결과 출력
print(df_one_hot)

4) 데이터 스케일링 (Data Scaling)
- 광고 영향도(Ad Influence), 제품 만족도(Product Satisfaction) 등 연속형 변수는 범위가 다를 수 있다.
- 변수의 범위가 너무 크면 보기 불편하므로 데이터 스케일링을 한다 (ex. 모든 데이터 값을 0~1사이로 맞추면 보기 편해진다)
- 따라서 모델 학습과 비교를 위해 정규화(Normalization) 또는 표준화(Standardization) 적용이 필요하다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df[["Ad Influence", "Product Satisfaction"]] = scaler.fit_transform(df[["Ad Influence", "Product Satisfaction"]])
print(df)

5) 피처 엔지니어링 (Feature Engineering)
- 그로스 마케팅에서는 기존 데이터를 가공하여 새로운 인사이트를 얻을 수 있는 변수를 추가하는 것이 중요하다.
- 예를 들어, 만족도 점수를 기반으로 고객을 그룹화할 수 있다.
# 제품 만족도 점수가 4 이상이면 "High", 그렇지 않으면 "Low"
df["Satisfaction Level"] = df["Product Satisfaction"].apply(lambda x: "High" if x >= 0.8 else "Low")
print(df)
3. 데이터 변환 상세
1) 결측값을 평균(Mean) 또는 중앙값(Median)으로 대체
(1) 평균(Mean)으로 대체
- 평균은 모든 데이터의 합을 데이터 개수로 나눈 값이다.
- 장점: 이상치(극단값)가 적은 경우 효과적이다.
- 단점: 이상치가 존재하면 평균이 왜곡될 수 있다.
import pandas as pd
import numpy as np
# 예제 데이터 생성
data = {
"User ID": [101, 102, 103, 104, 105],
"Ad Clicks": [10, 50, np.nan, 30, 60], # 결측값 포함
"Conversion Rate": [0.02, 0.05, 0.03, np.nan, 0.07] # 결측값 포함
}
df = pd.DataFrame(data)
# 평균으로 결측값 대체
df["Ad Clicks"].fillna(df["Ad Clicks"].mean())
df["Conversion Rate"].fillna(df["Conversion Rate"].mean())
print(df)
출력 결과
| User ID | Ad Clicks | Conversion Rate |
| 101 | 10.0 | 0.02 |
| 102 | 50.0 | 0.05 |
| 103 | 37.5 | 0.03 |
| 104 | 30.0 | 0.0425 |
| 105 | 60.0 | 0.07 |
(2) 중앙값(Median)으로 대체
- 중앙값은 데이터를 정렬한 후 가운데 위치한 값이다.
- 장점: 이상치(극단값)의 영향을 덜 받음
- 단점: 데이터가 정규분포를 따를 경우, 평균이 더 나은 선택일 수 있음
# 중앙값으로 결측값 대체
df["Ad Clicks"].fillna(df["Ad Clicks"].median())
df["Conversion Rate"].fillna(df["Conversion Rate"].median())
print(df)
출력 결과
| User ID | Ad Clicks | Conversion Rate |
| 101 | 10.0 | 0.02 |
| 102 | 50.0 | 0.05 |
| 103 | 30.0 | 0.03 |
| 104 | 30.0 | 0.04 |
| 105 | 60.0 | 0.07 |
(3) 평균과 중앙값 대체 방법 비교
| 방법 | 장점 | 단점 | 추천 상황 |
| 평균(Mean) 대체 | 데이터의 전체적인 대표값을 유지 | 이상치(극단값)가 있으면 왜곡될 가능성 있음 | 이상치가 적고 정규분포를 따르는 경우 |
| 중앙값(Median) 대체 | 이상치(극단값)의 영향을 받지 않음 | 정규분포를 따르는 경우, 평균보다 대표성이 떨어질 수 있음 | 이상치가 많은 경우 |
- 결측값이 적고, 데이터가 정규 분포를 따르는 경우 평균(Mean)으로 대체하는 것이 적합하다.
- 광고 클릭 수, 전환율과 같은 정량적 마케팅 데이터 처리에 유용하다.
- 이상치가 많거나 데이터의 분포가 비대칭인 경우 중앙값(Median)으로 대체하는 것이 효과적이다.
- 고객의 지출 금액, 고객 연령 등 이상치(극단값)의 영향을 받기 쉬운 데이터에서 유용하다.
- 그로스 마케팅에서는 결측값 처리를 통해 데이터 품질을 개선하고, 광고 캠페인 성과 분석 및 고객 행동 예측의 정확성을 높일 수 있다.
2) 데이터 타입 변환 상세
(1) 날짜 데이터를 요일로 변환
# 날짜 데이터 추가
df["Date"] = pd.to_datetime(["2024-02-01", "2024-02-02", "2024-02-03", "2024-02-04", "2024-02-05"])
# 요일 컬럼 추가
df["Day of Week"] = df["Date"].dt.day_name()
print(df)
3) 이상치 처리 (Outlier Handling)
- 클릭 수, 광고 비용 등이 **비정상적으로 높은 값(이상치)**일 경우, 처리해야 한다.
(1) 사분위 범위 (IQR, Interquartile Range) 이용한 이상치 제거
# 이상치 탐지
Q1 = df["Ad Clicks"].quantile(0.25)
Q3 = df["Ad Clicks"].quantile(0.75)
IQR = Q3 - Q1
# 이상치 제거
df_filtered = df[(df["Ad Clicks"] >= Q1 - 1.5 * IQR) & (df["Ad Clicks"] <= Q3 + 1.5 * IQR)]
print(df_filtered)
데이터 표준화 및 정규화
1. 데이터 표준화 및 정규화의 필요성
- 효과적인 비교를 위해 데이터 변환(Data Transformation)이 필수적이다.
- 대표적인 데이터 변환 기법
- 정규화(Normalization): 데이터를 0과 1 사이의 범위로 변환하여 상대적인 크기를 조정
- 표준화(Standardization): 데이터를 평균 0, 표준편차 1의 정규 분포 형태로 변환
- 표준화 또는 정규화하면 다음과 같은 장점이 있다.
- 서로 다른 크기를 가진 변수를 동일한 기준으로 비교할 수 있음
- 머신러닝 모델 학습 시, 특정 변수에 영향을 크게 받는 문제 방지
- 광고 캠페인 성과 분석에서 광고 영향도, 클릭 수, 제품 만족도 등의 비교 가능
2. 정규화(Normalization)
- 최소값을 0, 최대값을 1로 변환하며, 모든 값이 동일한 범위 내에 존재하도록 한다.
1) 정규화 예제 코드
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 예제 데이터 (광고 영향도, 제품 만족도)
data = {
"Ad Influence": [10, 50, 30, 80, 60],
"Product Satisfaction": [2, 4, 3, 5, 4]
}
df = pd.DataFrame(data)
# Min-Max Scaling 적용
scaler = MinMaxScaler()
df_normalized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print("Original Data:\\n", df)
print("\\nNormalized Data:\\n", df_normalized)
- 정규화 후 데이터 예시
| Ad Influence | Product Satisfaction |
| 0.00 | 0.00 |
| 0.50 | 0.67 |
| 0.25 | 0.33 |
| 1.00 | 1.00 |
| 0.75 | 0.67 |


3. 표준화(Standardization)
1) 표준화 개념
- 표준화는 데이터를 평균 0, 표준편차 1을 가지도록 변환하는 방법이다.
- 표준화를 수행하면 데이터가 평균 0을 중심으로 분포되며, 이상치의 영향을 줄이는 효과가 있다.

- 왼쪽 그래프: 원본 데이터
- 평균이 50, 표준편차가 15인 정규 분포 데이터를 생성하여 표현
- 파란색 히스토그램은 원본 데이터의 분포를 나타내며, 빨간색 곡선은 정규 분포를 시각적으로 표현한 것이다.
- 데이터의 중심이 평균 50에 모여 있고, 값들이 대칭적으로 퍼져 있다.
- 오른쪽 그래프: 표준화된 데이터
- 원본 데이터에서 평균을 빼고, 표준편차로 나누어 평균을 0, 표준편차를 1로 변환.
- 주황색 히스토그램은 변환된 데이터의 분포를 나타내며, 빨간색 곡선은 표준 정규 분포이다.
- 변환 후 데이터의 중심이 0이 되었으며, 동일한 분포 형태를 유지하지만 스케일이 조정되었다.
- 표준화 과정의 핵심
- 원본 데이터에서 평균을 빼고, 표준편차로 나누면 항상 평균이 0이 된다.
- 이를 통해 데이터의 상대적인 크기는 유지되면서 다른 특성과 비교가 용이해지고, 머신러닝 모델이 더 잘 학습할 수 있는 구조로 변경된다.
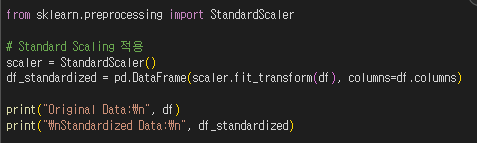
2) 표준화 예제 코드
from sklearn.preprocessing import StandardScaler
# Standard Scaling 적용
scaler = StandardScaler()
df_standardized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
print("Original Data:\\n", df)
print("\\nStandardized Data:\\n", df_standardized)
- 표준화 후 데이터 예시
| Ad Influence | Product Satisfaction |
| -1.41 | -1.41 |
| -0.14 | 0.71 |
| -0.78 | -0.35 |
| 1.55 | 1.41 |
| 0.78 | 0.71 |

4. 표준화 vs 정규화 비교
1) 방식
- 정규화 (Normalization): 데이터의 최소값과 최대값을 기준으로 0~1 범위로 변환하는 방식.
- 표준화 (Standardization): 데이터의 평균을 0, 표준편차를 1로 변환하여 정규 분포 형태로 조정하는 방식.
2) 특징
- 정규화: 값의 크기를 조절하여 상대적 크기를 비교할 수 있도록 함.
- 표준화: 평균 중심으로 데이터 분포를 조정하여 데이터가 정규 분포에 가깝도록 만듦.
3) 사용처
- 정규화: 값의 범위가 일정하고 상대적 비교가 중요한 경우 (예: 클릭률, 구매율).
- 표준화: 데이터가 정규 분포를 따르거나 다양한 크기의 데이터를 다룰 때 (예: 광고 예산, 판매량).
'⚠️그로스마케터 성장 보고합니다⚠️' 카테고리의 다른 글
| GM. 통계분석 기초1 (통계, 데이터 분포와 확률, 회귀분석, 단순회귀, 다중회귀) (0) | 2025.03.08 |
|---|---|
| GM. 데이터수집 및 전처리3 (데이터 구조 파악-EDA, 데이터 전처리 종합 실습, 그로스마케터, 마케팅보고서, 그래프시각화) (2) | 2025.03.05 |
| GM. 데이터수집 및 전처리1 (웹 크롤링, API, API 데이터 수집, 마케팅 보고서만들기) (7) | 2025.03.03 |
| GM. 데이터분석 개론 정리4 (JOIN, UNION, 고급 SQL-집계 함수와 그룹화, Python과 SQL 연동) (0) | 2025.03.03 |
| GM. 데이터분석 개론 정리3 (SQL 기본문법, SQL 용어 정리, 테이블 생성 및 데이터 삽입, 데이터 수정 및 삭제) (0) | 2025.03.03 |



