웹 크롤링 개요 및 기본 사용법
1. 그로스 마케팅에서 크롤링과 목적
- 웹 크롤링(Web Crawling)은 웹사이트에서 데이터를 자동으로 수집하는 기술이다. 크롤러(Crawler) 또는 스크래퍼(Scraper)라고 불리는 프로그램이 웹페이지의 HTML을 가져와 특정 정보를 추출하는 방식으로 동작한다.
- 크롤링은 뉴스, 상품 가격, 리뷰, 통계 데이터 등 다양한 정보를 자동으로 수집하는 데 활용되며, 검색 엔진, 가격 비교 사이트, 데이터 분석 등의 분야에서 필수적인 기술이다.
- 그로스 마케팅(Growth Marketing)에서 크롤링(Crawling)은 데이터를 자동으로 수집하여 마케팅 전략을 최적화하고 의사 결정을 개선하는 데 중요한 역할을 한다.
1) 경쟁사 및 시장 동향 분석
- 경쟁사의 가격 정책, 프로모션, 마케팅 전략 등을 실시간으로 추적하여 경쟁 우위를 확보할 수 있음.
- 업계 트렌드를 분석하여 소비자 선호도 변화를 빠르게 감지하고 마케팅 전략을 조정하는 데 활용.
2) 소비자 행동 및 리뷰 분석
- 소셜 미디어, 블로그, 쇼핑몰 리뷰 데이터를 크롤링하여 소비자의 제품 선호도, 불만 사항, 피드백을 분석.
- 이를 통해 제품 개선 및 맞춤형 마케팅 캠페인 기획 가능.
3) 광고 최적화 및 키워드 분석
- 검색 엔진 및 SNS에서 검색 트렌드, 인기 키워드를 수집하여 광고 및 SEO 전략 수립.
- 소비자가 많이 검색하는 키워드를 활용하여 광고 성과 극대화 및 타겟팅 강화.
4) 리드(잠재 고객) 발굴
- 특정 산업군의 기업 웹사이트나 채용 공고 데이터를 크롤링하여 B2B 마케팅 리드 발굴.
- 소셜미디어에서 특정 관심사를 가진 사용자 그룹을 식별하여 맞춤형 마케팅 진행.
5) 가격 비교 및 동적 가격 조정
- 경쟁사의 가격을 크롤링하여 실시간으로 가격을 조정하는 다이내믹 프라이싱(Dynamic Pricing) 전략 적용.
- 마켓플레이스에서 동일한 제품의 최저가 및 평균 가격을 분석하여 가격 정책을 최적화.
6) 콘텐츠 마케팅 전략 수립
- 인기 있는 블로그, 뉴스, SNS 콘텐츠를 분석하여 소비자가 관심을 가지는 주제를 파악.
- 이를 바탕으로 블로그, 유튜브, 뉴스레터 등에서 효과적인 콘텐츠 제작 가능.
7) 제품 수요 예측 및 재고 관리
- 이커머스 플랫폼에서 특정 제품의 판매 데이터와 검색량을 크롤링하여 수요 예측.
- 이를 통해 효율적인 재고 관리 및 마케팅 캠페인 기획 가능.
8) SNS 및 커뮤니티 모니터링
- 트위터, 인스타그램, 유튜브, 레딧 등의 데이터를 크롤링하여 특정 브랜드나 제품에 대한 소셜 리스닝(Social Listening) 수행.
- 브랜드 인지도, 소비자 반응, 바이럴 마케팅 효과 분석 가능.
2. 크롤링 방법
1) 정적 크롤링
- 웹사이트의 HTML 소스를 직접 요청하여 데이터를 가져오는 방식이다.
- 주로 requests, BeautifulSoup, lxml 등의 라이브러리를 사용하며, 정적 크롤링이 가능한 사이트는 크롤링 속도가 빠르고, 자동화 차단이 적다.
- 구글 뉴스 검색 결과를 가져오는 것이 정적 크롤링의 예시이다.
2) 동적 크롤링
- 웹사이트가 JavaScript를 사용하여 데이터를 동적으로 로드하는 경우, 일반적인 HTTP 요청만으로는 데이터를 가져올 수 없다.
- 이러한 웹사이트에서는 실제 브라우저를 실행하는 방식으로 크롤링해야 하며, Selenium, Playwright 등의 라이브러리를 활용한다.
- 예를 들어, Google Shopping 페이지에서 검색 버튼을 클릭해야만 상품 정보가 나타나는 경우, Selenium을 이용해 자동으로 클릭하고 데이터를 가져와야 한다.
3) API 기반 크롤링
- 일부 웹사이트는 크롤링을 허용하는 대신 API(Application Programming Interface)를 제공한다.
- API는 정해진 형식(JSON, XML 등)으로 데이터를 반환하며, 크롤링보다 안정적이고 빠르다.
- 예를 들어, 뉴스 데이터를 가져오려면 Google News API 또는 NYTimes API를 활용할 수 있다.
3. 크롤링 종류
1) 검색 엔진 크롤링
- 검색 엔진(예: Google, Bing, Naver)은 전 세계 웹사이트를 크롤링하여 검색 결과에 반영한다.
- 이러한 크롤러는 주기적으로 웹페이지를 방문하여 새로운 정보를 수집하고, 색인(indexing)하는 역할을 한다.
- Google의 Googlebot이 대표적인 검색 엔진 크롤러이다.
2) 뉴스 크롤링
- 뉴스 기사를 자동으로 수집하는 방식이다.
- 예를 들어, Google 뉴스 검색 결과를 크롤링하여 특정 키워드(예: "AI 기술")에 대한 최신 기사를 가져올 수 있다.
- 이 방식은 requests와 BeautifulSoup을 사용해 정적 크롤링 방식으로 구현할 수 있다.
3) 쇼핑 크롤링
- 상품 정보(가격, 할인 정보, 리뷰 등)를 자동으로 수집하는 방식이다.
- 예를 들어, Google Shopping, Amazon, 쿠팡 등에서 특정 상품을 검색한 후 가격 변동을 모니터링하는 크롤링을 구현할 수 있다.
- 일부 쇼핑몰은 동적 로딩을 사용하므로 Selenium과 같은 도구를 활용해야 한다.
4) 소셜 미디어 크롤링
- 트위터, 인스타그램, 페이스북과 같은 소셜 미디어에서 특정 키워드가 포함된 게시글이나 댓글을 자동으로 수집하는 방식이다.
- 일반적으로 소셜 미디어는 자동화된 크롤링을 차단하는 경우가 많아, API를 사용하는 것이 일반적이다.
- 예를 들어, Twitter API를 활용하면 특정 해시태그(#)가 포함된 트윗을 검색할 수 있다.
5) 데이터 분석용 크롤링
- 기업이나 연구기관에서는 특정 산업의 데이터를 수집하여 분석하는 용도로 크롤링을 활용한다.
- 예를 들어, 주식 시장 데이터를 크롤링하여 주가 변동을 분석하거나, 날씨 데이터를 수집하여 기후 변화를 연구할 수 있다.
4. 크롤링 시 주의할 점
- 로봇 배제 표준(Robots.txt) 준수크롤링을 시도하기 전에 해당 사이트의 robots.txt 파일을 확인하는 것이 중요하다.
- 웹사이트에는 robots.txt라는 파일이 있으며, 크롤러가 접근 가능한 페이지를 지정한다.
- 과도한 요청 방지이를 방지하기 위해 요청 간격을 조절하거나 time.sleep()을 사용하는 것이 좋다.
- 웹사이트에 짧은 시간 동안 너무 많은 요청을 보내면 IP 차단이 될 수 있다.
- 법적 문제 고려웹사이트의 이용 약관을 반드시 확인하고, API가 제공되는 경우 이를 활용하는 것이 바람직하다.
- 크롤링한 데이터를 상업적으로 활용할 경우, 저작권 및 서비스 약관을 위반할 수 있다.
- 자동화 탐지 우회이 경우, User-Agent를 변경하거나 프록시를 활용하는 등의 방법으로 우회할 수 있다.
- 일부 웹사이트는 자동화된 접근을 차단하기 위해 CAPTCHA(자동입력방지문자) 또는 로그인 인증을 요구한다.
5. 크롤링 기본 사용법
- 아래는 requests와 BeautifulSoup을 사용하여 Google 뉴스에서 특정 키워드(예: "AI")를 검색하고, 뉴스 제목과 링크를 가져오는 코드이다.
6. 주요 상용 크롤링 서비스
- 아래는 웹 크롤링을 지원하는 대표적인 상용 서비스들이다.
서비스명 주요 기능 가격 특징 ScraperAPI IP 회피, CAPTCHA 우회, API 제공 월 $29~ 사용이 간단하고 속도가 빠름 Bright Data (구 Luminati) 고급 프록시, 대량 크롤링, 데이터 API 제공 종량제 전 세계 IP 제공, 기업용 크롤링 지원 Oxylabs 웹 스크래핑 전용 API, 프록시 네트워크 종량제 높은 보안성, 안정적인 성능 SerpAPI Google 검색 엔진 및 쇼핑, 뉴스 크롤링 지원 무료 5,000 요청, 이후 월 $50~ Google 전용 크롤링 최적화 Apify 크롤링 자동화, No-Code 스크래핑 가능 무료(소량), 유료(월 $49~) 초보자도 쉽게 사용 가능 DataScraper.io 웹사이트에서 표 및 리스트 데이터 추출 무료(제한적), 유료 플랜 있음 웹 기반 크롤링 지원
7. 추천 서비스별 특징 및 사용법
1) ScraperAPI
- 특징
- HTTP 요청을 보낼 때 프록시를 자동으로 설정하여 IP 차단을 방지.
- CAPTCHA 우회 기능이 있어 Google, Amazon 등의 크롤링 가능.
- 단순한 API 요청 방식으로 사용 가능.
- 사용법 (Python 예제)
import requests
api_key = "YOUR_SCRAPERAPI_KEY"
search_url = f"<https://api.scraperapi.com/?api_key={api_key}&url=https://www.google.com/search?q=노트북>"
response = requests.get(search_url)
if response.status_code == 200:
print(response.text)
else:
print("크롤링 실패:", response.status_code)
2) Bright Data (구 Luminati)
- 특징
- 기업용 웹 크롤링에 최적화된 고급 프록시 서비스 제공.
- Google, Amazon, LinkedIn 등의 크롤링 지원.
- IP 블록을 방지하는 회전 프록시 (Rotating Proxy) 기능.
- 사용법
from requests import get
proxy_url = "<http://username:password@proxy.brightdata.com:22225>"
headers = {"User-Agent": "Mozilla/5.0"}
response = get("<https://www.google.com/search?q=노트북>", proxies={"http": proxy_url, "https": proxy_url}, headers=headers)
if response.status_code == 200:
print(response.text)
else:
print("크롤링 실패:", response.status_code)
3) Oxylabs
- 특징
- 기업 및 연구기관용 대규모 크롤링 지원.
- AI 기반 크롤링 기술 제공.
- 다양한 API 지원 (SERP, eCommerce, Web Scraping API 등).
- 사용법
import requests
proxy_url = "<http://username:password@pr.oxylabs.io:7777>"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get("<https://www.google.com/search?q=노트북>", proxies={"http": proxy_url}, headers=headers)
if response.status_code == 200:
print(response.text)
else:
print("크롤링 실패:", response.status_code)
4) SerpAPI
- 특징
- Google 검색 결과 전용 API 제공 (일반 검색, 뉴스, 쇼핑, 지도 등).
- Google 자동화 방어 우회 (IP 차단 및 CAPTCHA 문제 없음).
- JSON 형식으로 데이터 제공.
- 사용법 (Google 뉴스 검색)
import requests
api_key = "YOUR_SERPAPI_KEY"
params = {
"q": "인공지능",
"tbm": "nws",
"api_key": api_key
}
response = requests.get("<https://serpapi.com/search>", params=params)
if response.status_code == 200:
news_results = response.json().get("news_results", [])
for news in news_results[:10]:
print(news["title"], news["link"])
else:
print("크롤링 실패:", response.status_code)
5) Apify
- 특징
- 웹 기반 크롤링 플랫폼으로 코딩 없이 자동화 가능.
- 구글 검색, 쇼핑몰, SNS 크롤링 지원.
- JSON 또는 CSV 형식으로 데이터 제공.
- 사용법 (Google 뉴스 크롤링)
import requests api_url = "<https://api.apify.com/v2/actor-tasks/YOUR_TASK_ID/run-sync?token=YOUR_API_TOKEN>" response = requests.get(api_url) if response.status_code == 200: print(response.json()) # JSON 데이터 출력 else: print("크롤링 실패:", response.status_code)
8. 크롤링 서비스 선택 가이드
| 사용 목적 | 추천 서비스 |
| Google 검색, 뉴스, 쇼핑 크롤링 | SerpAPI, ScraperAPI |
| 대규모 웹사이트 크롤링 (Amazon, SNS 등) | Bright Data, Oxylabs |
| 코딩 없이 크롤링 자동화 | Apify |
| 연구 및 분석용 데이터 수집 | Bright Data, Oxylabs |
| 빠르고 간단한 웹 크롤링 | ScraperAPI |
API의 개념과 활용
1. API란 무엇인가?
- API(Application Programming Interface)는 애플리케이션 간의 데이터를 주고받고 기능을 호출할 수 있도록 하는 인터페이스이다. 이를 통해 기업은 외부 서비스와 연동하여 데이터를 수집하고, 마케팅 자동화를 구현하며, 맞춤형 고객 경험을 제공할 수 있다.
2. API의 역할과 중요성 in 그로스 마케팅
- 그로스 마케팅(Growth Marketing)은 데이터 기반으로 고객 유입, 전환, 유지 전략을 최적화하는 방식이다.
- API를 활용하면 다양한 마케팅 채널에서 데이터를 수집하고 분석하여 신속한 의사 결정을 내릴 수 있다.
- 데이터 통합 및 분석: 여러 마케팅 채널(Facebook Ads, Google Analytics, CRM 등)에서 데이터를 수집하여 분석.
- 개인화 마케팅: 고객 행동 데이터를 기반으로 맞춤형 이메일, 푸시 알림, 광고 캠페인 실행.
- 마케팅 자동화: API를 활용한 캠페인 자동화, 고객 세그먼트 분류 및 리타겟팅 전략 적용.
- A/B 테스트 최적화: API를 통해 다양한 버전의 콘텐츠를 동적으로 제공하고 성과 분석.
3. 그로스 마케팅에서 활용 가능한 API 유형
- API를 통해 마케팅을 자동화하고 확장성을 높일 수 있다. 대표적인 API 유형과 활용 사례는 다음과 같다.
(1) 광고 API
- Google Ads API / Facebook Marketing API
- 광고 캠페인을 자동 생성 및 관리.
- 특정 타겟 그룹을 설정하여 효율적인 광고 집행.
- 광고 성과 데이터를 실시간으로 분석하고 최적화.
(2) 분석 및 트래킹 API
- Google Analytics API
- 웹사이트 및 앱의 사용자 데이터를 실시간 수집.
- 유입 경로, 페이지 이탈률, 전환율 등의 핵심 지표 분석.
- 마케팅 성과에 따른 자동 보고서 생성.
(3) CRM 및 고객 데이터 API
- HubSpot API / Salesforce API
- 고객의 구매 이력, 문의 기록을 실시간으로 분석하여 맞춤형 마케팅 진행.
- 고객 세그먼트를 분류하여 개인화된 이메일 캠페인 자동화.
- 고객 유입부터 구매까지의 여정을 추적하고 자동 리타겟팅 실행.
(4) 이메일 & 메시징 API
- Twilio API / SendGrid API
- 고객 행동에 따라 이메일, SMS, 푸시 알림을 자동 발송.
- 결제 알림, 장바구니 이탈 방지 메시지, 프로모션 메시지 등 자동화.
- API를 이용해 A/B 테스트 실행 및 최적의 마케팅 메시지 도출.
(5) 소셜 미디어 API
- Twitter API / Instagram Graph API
- 소셜 미디어 데이터를 분석하여 트렌드 파악 및 해시태그 최적화.
- 브랜드 언급 모니터링을 통해 실시간 고객 피드백 수집.
- 자동 포스팅 및 사용자 참여 데이터 분석.
4. API를 활용한 그로스 마케팅 전략
API를 적용한 마케팅 전략을 구체적으로 살펴보면 다음과 같다.
(1) 자동화된 고객 세그멘테이션
- Google Analytics API + CRM API를 결합하여 고객 데이터를 자동 분류.
- 구매 패턴, 방문 빈도, 관심 제품 등을 기준으로 고객을 세그먼트화.
- 세그먼트별 맞춤형 광고 및 이메일 캠페인 실행.
(2) 마케팅 캠페인 자동화
- Facebook Ads API를 활용하여 특정 고객 그룹을 대상으로 광고 자동 집행.
- SendGrid API로 특정 행동을 한 고객에게 자동 이메일 전송 (예: 장바구니 이탈 고객 리마인드).
- Twilio API를 사용해 결제 완료 후 고객에게 SMS로 프로모션 코드 발송.
(3) 실시간 트래킹 및 성과 분석
- API 기반으로 실시간 대시보드를 구축하여 마케팅 성과를 추적.
- 광고 성과를 분석하고 자동으로 광고 예산 재조정.
- 소셜 미디어 API를 이용해 실시간 브랜드 언급 및 고객 반응 모니터링.
(4) 리타겟팅 및 개인화 마케팅
- 고객의 웹사이트 방문 데이터를 API로 분석하여 맞춤형 광고 제공.
- HubSpot API와 결합하여 고객 맞춤형 이메일 마케팅 실행.
- AI 기반 추천 API(OpenAI API 등)를 활용하여 고객 맞춤형 제품 추천.
5. API 활용 시 고려해야 할 사항
- 데이터 보안 및 개인정보 보호: API 사용 시 GDPR, CCPA 등 데이터 보호 규정을 준수해야 한다.
- API 요청 제한(Rate Limit): 특정 API는 요청 횟수 제한이 있으며, 효율적인 API 호출 전략이 필요하다.
- 데이터 동기화 문제: 여러 API에서 데이터를 가져올 경우 실시간 동기화를 고려해야 한다.
- API 업데이트 및 유지보수: 사용 중인 API의 버전이 업데이트되거나 폐기될 수 있어 지속적인 관리가 필요하다.
6. API를 활용한 그로스 마케팅의 기대 효과
- 개발 시간 단축: 기존 서비스와의 연동을 통해 빠른 구현 가능.
- 마케팅 자동화: 수동 프로세스를 줄이고 효율적인 마케팅 캠페인 운영.
- 데이터 기반 의사 결정: 실시간 데이터 분석으로 최적화된 마케팅 전략 수립.
- 고객 경험 향상: 개인화된 마케팅을 통해 고객 만족도 증가.
API 데이터 수집 심화
1. Google Analytics에서 가져온 데이터의 주요내용 분석하기
1) 사용자 행동 분석
| 분석 항목 | 설명 |
| Sessions (세션 수) | 사용자가 사이트를 방문한 횟수. 세션은 30분 동안 활동이 없으면 종료됨. |
| Users (사용자 수) | 특정 기간 동안 웹사이트를 방문한 고유 사용자 수. |
| New Users (신규 사용자 수) | 처음 방문한 사용자 수. |
| Pageviews (페이지뷰 수) | 웹사이트에서 조회된 페이지의 총 수. |
| Pages per Session (세션당 페이지뷰) | 방문자가 한 세션 동안 조회한 평균 페이지 수. |
2) 데이터 생성 및 CSV 저장 코드
import pandas as pd
# 하드코딩된 Google Analytics 사용자 행동 데이터 (30일)
data = {
"Date": pd.date_range(start="2024-01-01", periods=30, freq="D"),
"Sessions": [
1000, 1200, 1100, 1300, 1150, 1400, 1250, 1500, 1350, 1600,
1700, 1800, 1750, 1900, 1850, 1950, 2000, 2100, 2200, 2300,
2250, 2400, 2500, 2600, 2700, 2800, 2900, 3000, 3100, 3200
],
"Users": [
800, 950, 870, 1000, 920, 1100, 980, 1200, 1050, 1300,
1400, 1450, 1350, 1500, 1400, 1550, 1600, 1700, 1750, 1850,
1800, 1950, 2000, 2100, 2200, 2300, 2350, 2450, 2500, 2600
],
"New_Users": [
300, 400, 350, 450, 380, 500, 420, 550, 460, 600,
620, 650, 640, 700, 680, 720, 750, 800, 850, 900,
870, 950, 1000, 1050, 1100, 1150, 1200, 1250, 1300, 1350
],
"Pageviews": [
4000, 4500, 4200, 4800, 4300, 5000, 4600, 5200, 4800, 5500,
6000, 6500, 6200, 7000, 6800, 7200, 7500, 7800, 8000, 8200,
8500, 8700, 9000, 9500, 9800, 10000, 10500, 11000, 11500, 12000
],
"Pages_per_Session": [
4.0, 3.8, 3.9, 3.7, 3.8, 3.6, 3.7, 3.5, 3.6, 3.4,
3.9, 4.0, 3.8, 4.1, 4.2, 4.0, 4.3, 4.5, 4.4, 4.6,
4.2, 4.1, 4.3, 4.5, 4.6, 4.7, 4.8, 4.9, 5.0, 5.1
]
}
# 데이터프레임 생성
google_analytics_data = pd.DataFrame(data)
# CSV 파일로 저장
csv_filename = "google_analytics_data.csv"
google_analytics_data.to_csv(csv_filename, index=False)
print(f"CSV 파일 '{csv_filename}' 저장 완료!")
3) CSV 로드 및 데이터 분석, 시각화 코드
import matplotlib.pyplot as plt
# CSV 파일 로드
csv_filename = "google_analytics_data.csv"
google_analytics_data = pd.read_csv(csv_filename)
# 주요 지표 계산
total_sessions = google_analytics_data["Sessions"].sum()
total_users = google_analytics_data["Users"].sum()
total_new_users = google_analytics_data["New_Users"].sum()
total_pageviews = google_analytics_data["Pageviews"].sum()
avg_pages_per_session = round(google_analytics_data["Pages_per_Session"].mean(), 2)
# 신규 사용자 비율 계산
new_user_ratio = round((total_new_users / total_users) * 100, 2)
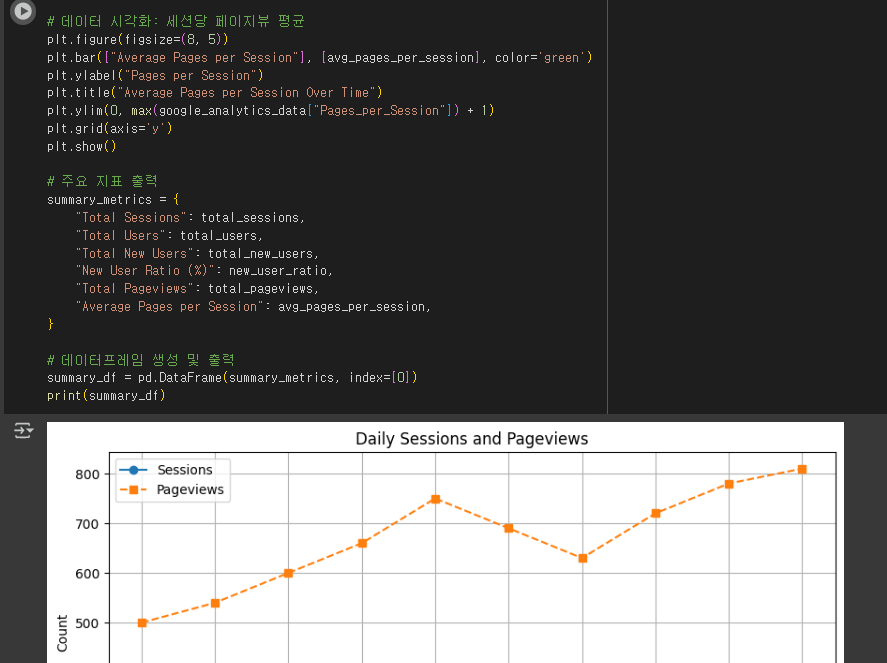
# 데이터 시각화: 세션 수 및 페이지뷰 수
plt.figure(figsize=(10, 5))
plt.plot(google_analytics_data["Date"], google_analytics_data["Sessions"], label="Sessions", marker='o', linestyle='-')
plt.plot(google_analytics_data["Date"], google_analytics_data["Pageviews"], label="Pageviews", marker='s', linestyle='--')
plt.xlabel("Date")
plt.ylabel("Count")
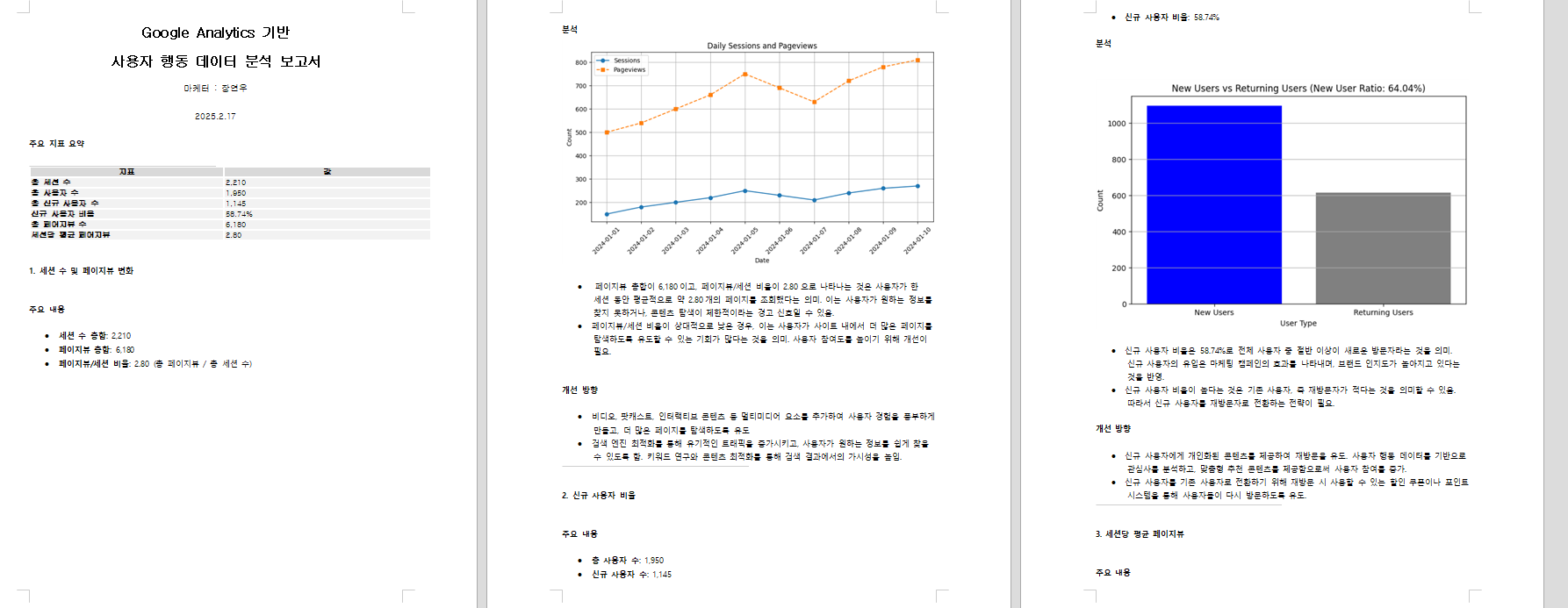
plt.title("Daily Sessions and Pageviews")
plt.legend()
plt.xticks(rotation=45)
plt.grid()
plt.show()
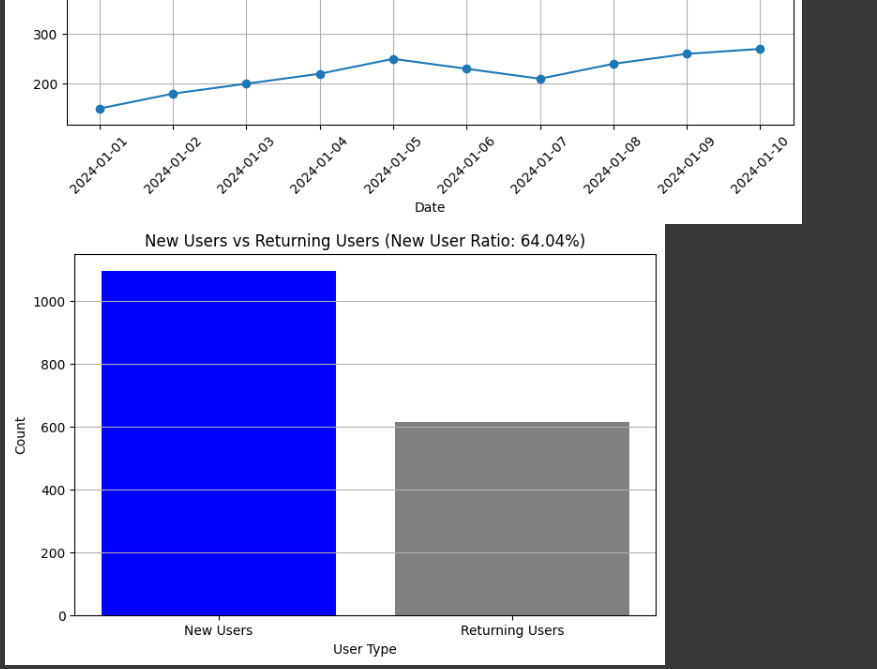
# 데이터 시각화: 신규 사용자 비율
plt.figure(figsize=(8, 5))
plt.bar(["New Users", "Returning Users"], [total_new_users, total_users - total_new_users], color=['blue', 'gray'])
plt.xlabel("User Type")
plt.ylabel("Count")
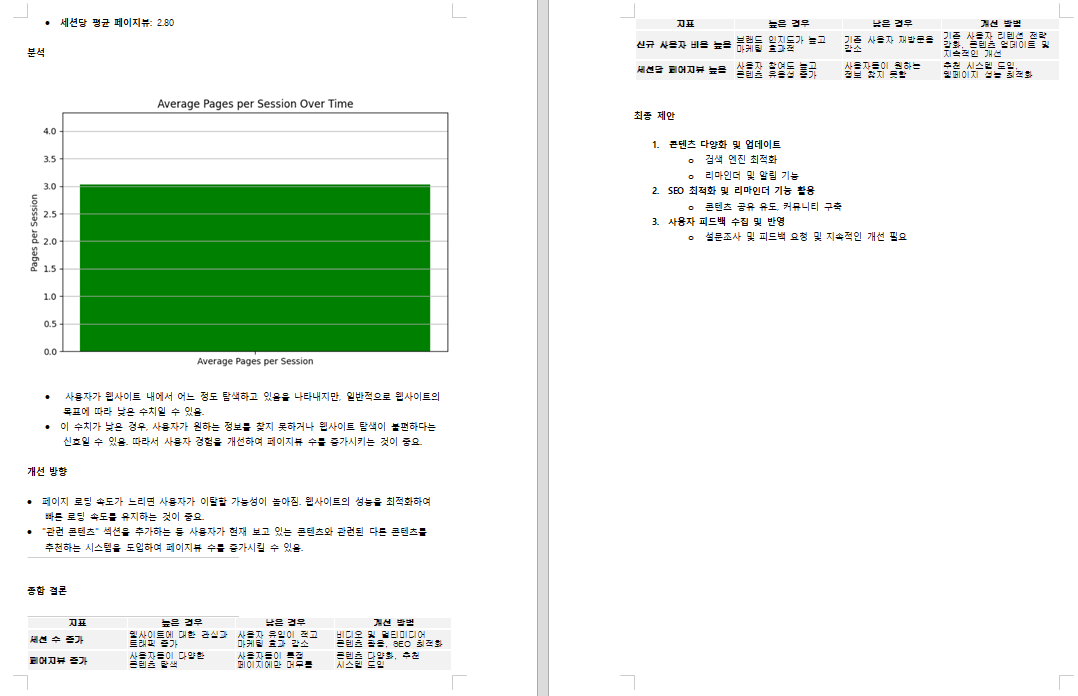
plt.title(f"New Users vs Returning Users (New User Ratio: {new_user_ratio}%)")
plt.grid(axis='y')
plt.show()
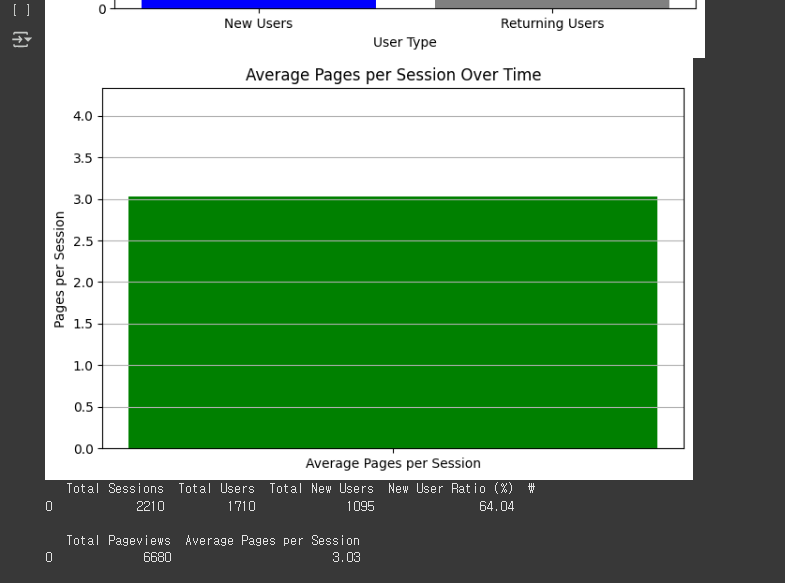
# 데이터 시각화: 세션당 페이지뷰 평균
plt.figure(figsize=(8, 5))
plt.bar(["Average Pages per Session"], [avg_pages_per_session], color='green')
plt.ylabel("Pages per Session")
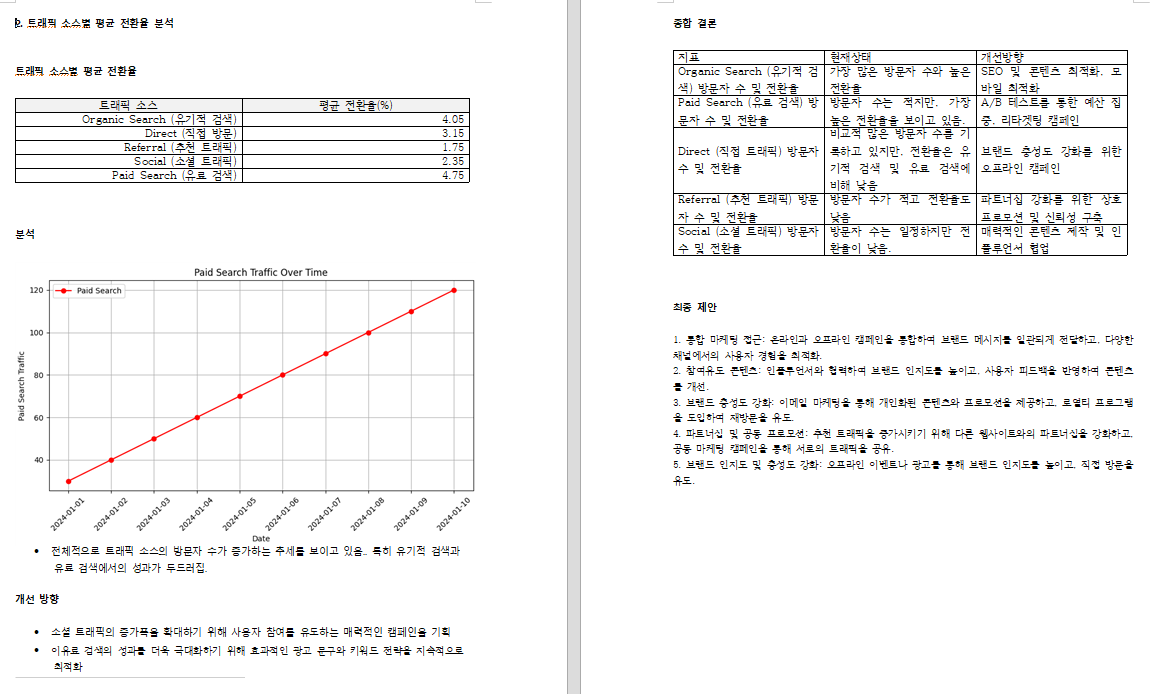
plt.title("Average Pages per Session Over Time")
plt.ylim(0, max(google_analytics_data["Pages_per_Session"]) + 1)
plt.grid(axis='y')
plt.show()
# 주요 지표 출력
summary_metrics = {
"Total Sessions": total_sessions,
"Total Users": total_users,
"Total New Users": total_new_users,
"New User Ratio (%)": new_user_ratio,
"Total Pageviews": total_pageviews,
"Average Pages per Session": avg_pages_per_session,
}
# 데이터프레임 생성 및 출력
summary_df = pd.DataFrame(summary_metrics, index=[0])
print(summary_df)
- 데이터 생성 및 저장
- 하드코딩된 데이터 (30일)을 사용하여 세션 수, 사용자 수, 신규 사용자 수, 페이지뷰, 세션당 페이지뷰 데이터를 생성.
- pandas.DataFrame을 활용하여 정리.
- to_csv()를 사용하여 google_analytics_data.csv로 저장.
- CSV 파일 로드 후 분석
- read_csv()를 사용하여 CSV 데이터를 로드.
- 주요 지표(총 세션 수, 총 사용자 수, 신규 사용자 비율 등) 계산.
- 데이터 시각화
- 세션 수 및 페이지뷰 변화 (라인 그래프)
- 신규 사용자 vs 기존 사용자 비율 (막대 그래프)
- 세션당 평균 페이지뷰 변화 (막대 그래프)