
귀찮아서 안할려고 했는데 도저히 수업을 따라갈 수 없어 꾸준히 해보겠다.
문과로서 산 삶 23년. 이제는 이과머리로 바꾸겠다.
Pandas 기초
1. Pandas 기초
1) Pandas란?
- Pandas는 Python에서 데이터 분석과 조작을 쉽게 할 수 있도록 도와주는 강력한 오픈소스 라이브러리이다.
- Pandas는 엑셀과 유사한 데이터 구조를 제공하며, 표 형태(테이블 형식)의 데이터를 효율적으로 다룰 수 있다.
- Pandas는 NumPy 기반으로 만들어졌으며, 데이터 정리, 변환, 분석, 시각화 등의 기능을 제공한다.
2) Pandas 설치 및 기본 사용법
- Pandas는 Python의 pip 패키지 관리자를 이용하여 쉽게 설치할 수 있다.
| pip install pandas |
- 설치가 완료되면, Pandas를 불러와서 사용할 수 있다.
| import pandas as pd # 일반적으로 'pd'라는 별칭으로 사용 |
3) Pandas의 주요 데이터 구조
- Series (1차원 데이터 구조): Series는 Pandas의 1차원 데이터 구조로, 리스트(List)와 유사하지만, 인덱스(Index)가 추가되어 데이터에 쉽게 접근할 수 있다.
| import pandas as pd # Series 생성 click_rates = pd.Series([0.05, 0.10, 0.15, 0.20], index=["A", "B", "C", "D"]) print(click_rates) #출력결과 A 0.05 B 0.10 C 0.15 D 0.20 dtype: float64 |
- DataFrame (2차원 데이터 구조): DataFrame은 엑셀의 표와 같은 2차원 데이터 구조로, 행과 열을 가집니다.
| # DataFrame 생성 data = { "Campaign": ["봄맞이 이벤트", "여름 할인", "가을 특별전"], "CTR": [0.12, 0.15, 0.08], "CR": [0.05, 0.07, 0.03] } df = pd.DataFrame(data) print(df) #출력결과 Campaign CTR CR 0 봄맞이 이벤트 0.12 0.05 1 여름 할인 0.15 0.07 2 가을 특별전 0.08 0.03 |
4) Pandas 주요 기능
- 데이터 읽기 및 저장: Pandas는 CSV, Excel, JSON 등 다양한 형식의 데이터를 읽고 저장할 수 있다.
| df = pd.read_csv("marketing_data.csv") # CSV 파일 불러오기 df.to_excel("output.xlsx", index=False) # 엑셀 파일로 저장 |
- 데이터 조회 및 탐색
- 데이터 로드 및 확인
- 특정 조건 필터링
- 기간별 조회
- 상위 N개 데이터 조회
- 광고비 대비 매출 비율 계산
#Colab에서 pandas dataframe을 표형식으로 출력하기 위해서는 print 대신 display를 사용한다.


- 데이터 필터링
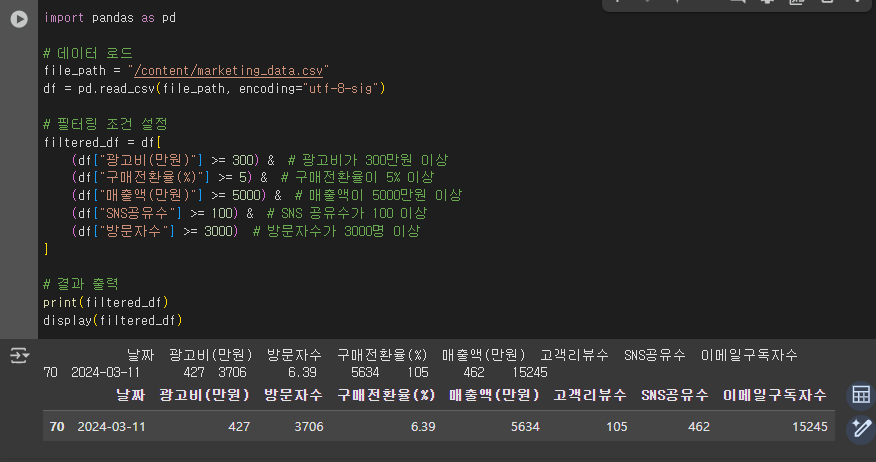
- 데이터 그룹화 - groupby(): 특정 열을 기준으로 데이터를 그룹화한 후, 합계, 평균, 개수 등의 집계 연산을 수행하는 기능
- 기본 사용법: df.groupby("그룹기준열").집계함수()
- df.groupby("카테고리")["매출액(만원)"].sum() -> 이 코드는 "카테고리" 열을 기준으로 그룹화하여 "매출액(만원)"의 합계를 계산한다.
- 주요 기능 정리기능코드
기능 코드 그룹별 합계 df.groupby("카테고리")["매출액(만원)"].sum() 그룹별 평균 df.groupby("카테고리")["매출액(만원)"].mean() 그룹별 개수 df.groupby("카테고리")["매출액(만원)"].count() 여러 개 그룹 기준 df.groupby(["카테고리", "지역"])["매출액(만원)"].mean() 여러 개 집계 연산 df.groupby("카테고리").agg({"매출액(만원)": "sum", "광고비(만원)": "mean"})


5) Pandas 활용 예제
- 제조업체를 위한 그로스 마케팅 예


2. Pandas 데이터 로드 및 기본 탐색
1) Pandas 데이터 로드 (Data Loading)
| 파일 형식 | 메서드 |
| CSV (Comma Separated Values) | pd.read_csv() |
| Excel (XLSX) | pd.read_excel() |
| JSON (JavaScript Object Notation) | pd.read_json() |
| SQL 데이터베이스 | pd.read_sql() |
| Parquet | pd.read_parquet() |
- CSV 파일 로드: Pandas의 read_csv() 함수
- encoding="utf-8" → 한글 데이터가 포함된 경우 encoding="cp949"을 사용할 수도 있음.
- delimiter="," → 데이터가 ,가 아닌 ;로 구분된 경우 delimiter=";"을 지정.
- 컬럼명을 지정하여 불러오기
- names=[] → 파일의 첫 번째 행이 컬럼명이 아닌 경우, 수동으로 컬럼명을 지정.
- header=0 → 첫 번째 행을 컬럼명으로 설정 (기본값).
| import pandas as pd # CSV 파일 불러오기 df = pd.read_csv("marketing_data.csv", encoding="utf-8", delimiter=",") # 데이터 확인 print(df.head()) # 상위 5개 행 출력 |
| df = pd.read_csv("marketing_data.csv", names=["Campaign", "Sales", "Clicks", "Conversions", "Region"], header=0) |
- Excel 파일 로드: read_excel() 메서드를 사용
- sheet_name="Sheet1" → 여러 개의 시트가 있는 경우 특정 시트 선택.
| df = pd.read_excel("marketing_data.xlsx", sheet_name="Sheet1") print(df.head()) |
- SON 파일 로드: read_json()을 사용
| df = pd.read_json("marketing_data.json") print(df.head()) |
- SQL 데이터베이스에서 불러오기
| import sqlite3 # 데이터베이스 연결 conn = sqlite3.connect("marketing.db") # SQL 쿼리를 이용해 데이터 가져오기 df = pd.read_sql("SELECT * FROM marketing_campaigns", conn) # 데이터 출력 print(df.head()) |
2) 데이터 기본 탐색 (Basic Exploration)
- 데이터 크기 확인: print(df.shape) - (행 개수, 열 개수)를 반환.
- 컬럼명 확인: print(df.columns)
- 데이터 정보 출력: print(df.info()) - 데이터 타입, 컬럼별 결측값 개수 등을 확인 가능.
- 데이터 타입 확인: print(df.dtypes) - 숫자가 아닌 열(예: object)을 변환할 필요가 있는지 점검.
- 데이터의 상위 및 하위 행 조회: print(df.head()) # 상위 5개 행 출력 / print(df.tail()) # 하위 5개 행 출력
- 기초 통계 요약: print(df.describe()) - count, mean, std(표준편차), min(최솟값), max(최댓값), 25%/50%/75%(사분위수) 등 제공.
- 결측값 확인: print(df.isnull().sum())
3.데이터 요약 정리
- 데이터 크기 확인 → .shape
- 컬럼명 확인 → .columns
- 데이터 정보 출력 → .info()
- 데이터 타입 확인 → .dtypes
- 데이터 샘플 확인 → .head(), .tail()
- 기초 통계 분석 → .describe()
- 고유값 확인 → .unique(), .value_counts()
- df["방문자수"].unique() # "카테고리" 열의 고유값 조회
- 결측값 확인 → .isnull().sum()
데이터 정렬과 필터링
1. Pandas 데이터 정렬 (단일/여러 열 기준 정렬)
1) sort_values()를 활용한 단일 열 정렬
- ascending=True → 오름차순(작은 값부터 큰 값 순서)
- ascending=False → 내림차순(큰 값부터 작은 값 순서)

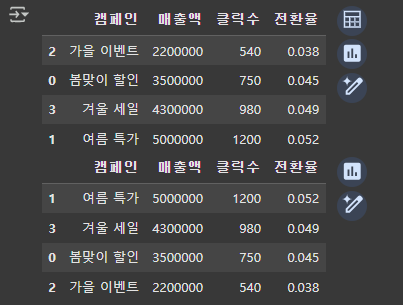
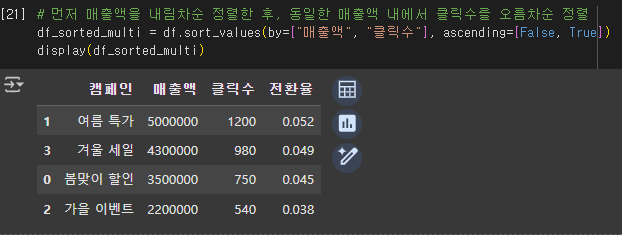
2) 여러 열 기준 정렬
- by=["매출액", "클릭수"] → 두 개의 열을 기준으로 정렬
- ascending=[False, True] → 첫 번째 기준(매출액)은 내림차순, 두 번째 기준(클릭수)은 오름차순 정렬
2. Pandas 데이터 필터링 (Filtering) - boolean indexing과 query()
1) boolean indexing을 활용한 필터링: 조건을 만족하는 행만 선택
- df["클릭수"] >= 800 → True 또는 False 값을 반환
- df[...] → True 값이 있는 행만 선택

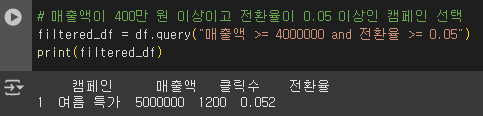
2) query()를 활용한 필터링: 직관적인 방식으로 필터링을 수행
- and → 두 개 이상의 조건을 동시에 만족하는 데이터 선택
- or → 두 개 이상의 조건 중 하나라도 만족하는 데이터 선택
3) 특정 값이 포함된 데이터 필터링: isin()을 사용하면 특정 목록에 포함된 값을 가진 행만 선택할 수 있다.
- isin(["봄맞이 할인", "겨울 세일"]) → 두 개의 캠페인만 포함하는 데이터 선택

4) 문자열을 포함하는 데이터 필터링: str.contains()를 활용하면 특정 단어가 포함된 데이터를 찾을 수 있다.

5) 특정 범위에 있는 데이터 필터링: between()을 사용하면 특정 범위 내에 있는 값을 필터링할 수 있다.
- between(3000000, 4500000) → 300만 원 이상, 450만 원 이하의 데이터 선택

3. 데이터 정렬과 필터링을 결합하기
- 매출액이 평균 이상인 캠페인 중, 클릭수 기준 오름차순 정렬
| # 매출액 평균 계산 mean_revenue = df["매출액"].mean() # 매출액이 평균 이상인 데이터 선택 후 클릭수 기준 오름차순 정렬 filtered_sorted_df = df[df["매출액"] >= mean_revenue].sort_values(by="클릭수", ascending=True) print(filtered_sorted_df) |
- 전환율이 특정 범위 내에 있는 캠페인 중, 클릭수 내림차순 정렬
| # 전환율이 0.04 이상 0.05 이하인 캠페인 선택 후 클릭수 내림차순 정렬 filtered_sorted_df = df[df["전환율"].between(0.04, 0.05)].sort_values(by="클릭수", ascending=False) print(filtered_sorted_df) |
- query()를 활용하여 다중 조건 필터링 후, 정렬
| # query()를 활용한 다중 조건 필터링 후 클릭수 기준 내림차순 정렬 filtered_sorted_df = df.query("매출액 >= 3000000 and 전환율 >= 0.045").sort_values(by="클릭수", ascending=False) print(filtered_sorted_df) |
4. 정리
| 기능사용 | 예제 |
| 단일 열 정렬 | df.sort_values(by="매출액", ascending=False) |
| 여러 열 기준 정렬 | df.sort_values(by=["매출액", "클릭수"], ascending=[False, True]) |
| 특정 조건 필터링 | df[df["클릭수"] >= 800] |
| 여러 조건 필터링 | df[(df["클릭수"] >= 800) & (df["전환율"] >= 0.05)] |
| query() 활용 | df.query("매출액 >= 4000000 and 전환율 >= 0.05") |
| 특정 값 포함 필터링 | df[df["캠페인"].isin(["봄맞이 할인", "겨울 세일"])] |
| 특정 단어 포함 필터링 | df[df["캠페인"].str.contains("할인")] |
| 특정 범위 필터링 | df[df["매출액"].between(3000000, 4500000)] |
데이터 그룹화 및 집계
1. 데이터 그룹화란?
- groupby()는 특정 열을 기준으로 데이터를 묶고, 이를 바탕으로 다양한 통계 연산을 수행하는 기능을 제공한다.
- 이를 활용하면 다음과 같은 분석이 가능하다.
- 캠페인별 매출 합산: 특정 마케팅 캠페인의 총 매출을 계산할 수 있다.
- 지역별 클릭 수 비교: 특정 지역에서 가장 많은 클릭 수를 기록한 캠페인을 파악할 수 있다.
- 전환율 평균 분석: 여러 광고 캠페인의 평균 전환율을 비교할 수 있다.
2. 예제 데이터 생성
- 그로스 마케팅 데이터를 활용하여 캠페인별 매출, 클릭 수, 전환율 등의 정보를 포함하는 데이터셋을 생성한다.


3. 단일 열 기준으로 데이터 그룹화
1) 캠페인별 매출 합산
- 같은 캠페인명을 기준으로 데이터를 묶고, 매출액을 합산하였다.

2) 캠페인별 평균 클릭 수
- 각 캠페인의 평균 클릭 수를 계산하였다.

4. 여러 개의 열을 기준으로 그룹화
1) 캠페인과 지역별 매출 합계
- ["캠페인", "지역"]을 기준으로 데이터를 묶고 매출액을 합산하였다.
2) 캠페인과 지역별 클릭수 평균
- 캠페인별, 지역별로 그룹화한 후 평균 클릭수를 계산하였다.
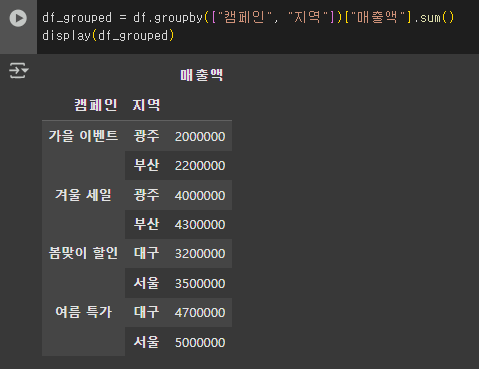

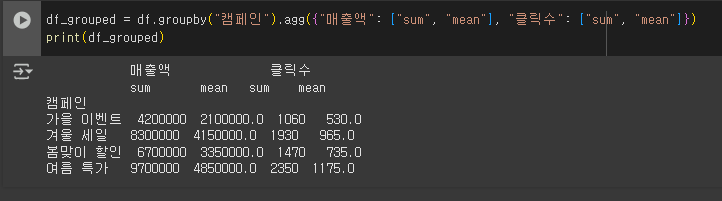
5. 그룹화된 데이터에서 여러 개의 집계 연산 적용하기
1) 캠페인별 매출액과 클릭수에 대한 집계 연산 적용
- agg()를 사용하여 sum과 mean 두 개의 연산을 적용하였다.
6. 그룹화된 데이터 필터링
1) 매출액 합계가 700만 원 이상인 캠페인만 선택
- df.groupby("캠페인")["매출액"].sum()으로 그룹화한 후, 700만 원 이상인 데이터만 필터링하였다.

데이터 분석을 활용한 그로스 마케팅 프로모션 원칙과 절차
1. 그로스 마케팅 프로모션의 핵심 원칙
: 그로스 마케팅(Growth Marketing)은 데이터 기반 최적화, 지속적인 실험, 고객 행동 분석을 통해 빠르게 성장할 수 있는 전략을 찾는 과정이다
- 타겟 고객 세분화(Segmentation)
- 다양한 고객층을 분석하여 소비 패턴이 유사한 그룹으로 나누고 맞춤형 프로모션을 실행
- 예: 외출이 적은 1인 가구 vs. 직장인 vs. 커뮤니케이션이 적은 소비층
- 데이터 기반 실험(Experimentation)
- 가설을 세우고 A/B 테스트 또는 소규모 프로모션을 실행한 후 반응을 데이터로 측정하여 최적화
- 예: "월 정기 배송 50% 할인" vs. "첫 구매 5천 원 할인" 중 더 높은 전환율을 확인
- 맞춤형 개인화(Personalization)
- 고객 데이터를 활용하여 개별 맞춤형 프로모션 제공
- 예: OTT 소비량이 높은 지역에는 넷플릭스 구독 프로모션, 직장인 밀집 지역에는 야간 배달 프로모션
- 바이럴 요소 활용(Viral Growth)
- SNS 공유, 친구 추천 리워드, 입소문 유도 등 유저 기반 성장 전략 적용
- 예: "친구 추천 시 1개월 무료", "소셜미디어 인증 시 추가 할인"
- 성장 지표 측정(Tracking & Optimization)
- 프로모션 이후 구매 전환율, 고객 유지율, CAC(고객 획득 비용) 등 주요 지표를 측정하여 최적화
- 예: "재구매율 20% 증가 vs. 신규 유입 30% 증가 중 어느 것이 효과적인가?"
2. 그로스 마케팅 프로모션 절차 예시
- 1단계: 데이터 분석을 통한 고객 타겟팅
- 먼저 데이터를 기반으로 타겟 고객을 세분화하고, 각 그룹별 소비 패턴과 니즈를 파악
- 결과 해석:
- 1인 가구 비율이 높은 지역에서는 배달 서비스, 무인 상점, 정기 구독 서비스의 수요가 높을 가능성이 큼
- 이 데이터를 바탕으로 특정 지역에서 실험적인 프로모션을 실행 가능
| df_new["1인가구_비율"] = (df_new["1인가구수"] / df_new["총인구"]) * 100 one_person_ratio = df_new.groupby("자치구")["1인가구_비율"].mean().sort_values(ascending=False) print(one_person_ratio.head(5)) |
- 2단계: 가장 적합한 상품 선정
- 각 고객 그룹별로 가장 잘 팔릴 상품을 선정하고, 맞춤형 프로모션 전략을 수립
- 예제 코드 (외출이 적은 지역에서 배달 서비스 수요 분석)
- 결과 해석:
- 외출이 적은 지역에서는 간편식, 신선식품 정기 배송, 온라인 쇼핑 관련 프로모션이 효과적일 가능성이 큼
| df_new["외출_적은_비율"] = (df_new["평일_외출이_적은_집단"] + df_new["휴일_외출이_적은_집단"]) / df_new["총인구"] * 100 low_outdoor_areas = df_new.groupby("자치구")["외출_적은_비율"].mean().sort_values(ascending=False) print(low_outdoor_areas.head(5)) |
- 3단계: 프로모션 전략 수립 및 실험 (A/B 테스트)
- 최적의 프로모션 방식을 찾기 위해 A/B 테스트를 실행하여 성과를 비교
- A/B 테스트 예제
- A안: "첫 구매 시 5천 원 할인"
- B안: "정기 배송 첫 달 50% 할인"
- 예제 코드 (직장인이 많은 지역에서 헬스케어 및 건강식품 수요 분석)
- 결과 해석:
- 직장인 비율이 높은 지역에서는 야간 헬스장 쿠폰, 단백질 보충제 할인, 건강식 배달 서비스 프로모션이 효과적일 가능성이 높음
| df_new["직장인_비율"] = (df_new["출근소요시간_및_근무시간이_많은_집단"] / df_new["총인구"]) * 100 high_work_areas = df_new.groupby("자치구")["직장인_비율"].mean().sort_values(ascending=False) print(high_work_areas.head(5)) |
- 4단계: 프로모션 실행 및 바이럴 마케팅 적용
- 최적의 프로모션을 실행하고, SNS, 친구 추천, 인플루언서 마케팅 등 바이럴 요소를 포함해야 합니다.
- SNS 마케팅 예제
- "구매 후 SNS 인증 시 추가 할인 제공"
- "친구 추천 시 1개월 무료 구독"
- 예제 코드 (동영상 서비스 이용이 많은 지역에서 OTT 및 스마트 기기 판매 분석)
- 결과 해석:
- 동영상 소비가 많은 지역에서는 넷플릭스, 웨이브 같은 OTT 서비스 할인, 스마트 TV 프로모션이 효과적일 가능성이 큼
| df_new["동영상_이용_비율"] = (df_new["동영상서비스_이용이_많은_집단"] / df_new["총인구"]) * 100 video_usage_areas = df_new.groupby("자치구")["동영상_이용_비율"].mean().sort_values(ascending=False) print(video_usage_areas.head(5)) |
- 5단계: 프로모션 성과 분석 및 최적화
- 실행한 프로모션의 효과를 측정하고 구매 전환율, 재구매율, CAC(고객 획득 비용) 등을 비교하여 최적화합니다.
- 측정해야 할 지표
- 전환율 (Conversion Rate): 프로모션을 본 후 실제 구매한 고객 비율
- 재구매율 (Retention Rate): 한 번 구매 후 다시 구매하는 고객 비율
- 고객 획득 비용 (CAC): 한 명의 신규 고객을 확보하는 데 드는 마케팅 비용
- 6단계: 반복 최적화 및 확장
- 가장 효과적인 프로모션 전략을 확인한 후, 더 많은 지역과 채널로 확장해야 한다.
- A/B 테스트 결과 전환율이 높은 프로모션을 전국적으로 확대
- 데이터 기반으로 새로운 고객 세그먼트 추가 분석 및 공략
- 기존 고객을 대상으로 추가 상품 크로스셀링(Cross-selling) 진행
- 가장 효과적인 프로모션 전략을 확인한 후, 더 많은 지역과 채널로 확장해야 한다.



