
멋쟁이사자처럼 그로스마케팅 부트캠프 시작~~~
4~5개월 시간동안 진짜 열심히 해야겠다~~~~~~~🤓
기초 이론 정리
1. 그로스마케팅이란?
- 그로스 마케팅은 데이터 기반의 실험과 최적화를 통해 지속적인 성장을 추구하는 마케팅 전략
- 그로스 해킹이 단기적인 사용자 증가에 초점을 맞췄다면, 그로스 마케팅은 장기적인 성장과 고객 유지를 포함하는 확장된 개념
- 단순한 고객 획득을 넘어 충성도 높은 고객을 확보하고, 지속적으로 고객과의 관계를 유지하는 전략으로 발전
- 그로스 마케팅을 도입해야 하는 이유는 빠르고 비용 효율적인 성장을 가능하게 하기 때문
- 전통적인 마케팅이 브랜딩과 광고 중심이라면, 그로스 마케팅은 데이터 분석과 최적화를 통해 지속적인 성과 개선을 목표로 한다.
2. 그로스 마케팅에서 데이터 분석이 중요한 이유
- 데이터 기반 의사 결정 → 마케팅 비용 절감
- 최적의 광고 및 UX/UI 디자인 선택 → 사용자 행동 분석을 통한 개선
- LTV(고객 생애 가치) 기반 고객 타겟팅 → 효율적인 마케팅 전략 구축
- A/B 테스트를 통한 지속적 실험과 최적화
- 코호트 분석을 활용한 사용자 이탈 감소 및 충성 고객 확보
3. 그로스 마케팅 실행 프로세스
| 1. 목표 설정 | 명확한 비즈니스 및 마케팅 목표 수립 | KPI 정의, 목표 설정 |
| 2. 데이터 수집 및 분석 | 사용자 행동 데이터 분석 | 웹사이트, CRM, 광고 데이터 분석 |
| 3. 가설 설정 및 실험 설계 | 개선점을 찾아 가설을 수립하고 실험 설계 | A/B 테스트, 퍼널 분석 |
| 4. 실험 실행 및 데이터 측정 | 실험 실행 후 성과 측정 및 분석 | 전환율, 클릭률, 유지율 분석 |
| 5. 최적화 및 확장 | 성공적인 전략을 확대하고 지속적인 최적화 진행 | 자동화, 글로벌 확장 |
4. 그로스 마케팅 전략의 주요 요소
1) 퍼널 분석(Funnel Analysis)
고객이 처음 브랜드를 접한 후, 구매(또는 목표 행동)까지 도달하는 과정을 분석하는 기법
대표적인 모델로 AARRR 퍼널(Pirate Metrics) 이 있다.
AARRR 프레임워크 (Acquisition → Activation → Retention → Revenue → Referral)
- Acquisition (획득) - 사용자가 서비스를 처음 접하는 단계 (예: 웹사이트 방문, 앱 다운로드)
- Activation (활성화) - 사용자가 처음으로 가치를 경험하는 단계 (예: 회원가입, 첫 구매)
- Retention (유지) - 사용자가 지속적으로 서비스를 사용하는 단계 (예: 앱 재방문, 정기 결제 유지)
- Revenue (수익화) - 사용자로부터 매출이 발생하는 단계 (예: 유료 결제, 광고 수익)
- Referral (추천) - 사용자가 친구나 가족에게 추천하는 단계 (예: 추천 코드, 바이럴 마케팅)
2) A/B 테스트(A/B Testing)와 최적화
마케팅 캠페인이나 UI/UX에서 두 가지 이상 버전을 실험하여 어떤 것이 더 높은 성과를 내는지 테스트하는 방법이다.
3) 바이럴 루프(Viral Loop)
기존 사용자가 새로운 사용자를 초대하여 네트워크 효과를 만드는 방식이다. 추천 보상 프로그램(Referral Marketing)이 대표적인 예시다.
4) 리타겟팅(Retargeting)과 개인화 마케팅
기존 방문자(잠재 고객)에게 맞춤형 광고를 제공하여 다시 방문하도록 유도하는 전략이다.
5) 구독 및 재구매 유도 전략
한 번 구매한 고객이 반복 구매하도록 유도하는 전략이다.
Python 기초
1. Python Grammar
1) 변수(Variable): 데이터를 저장하기 위한 메모리 공간을 의미.
- 변수 선언과 값 할당: = 대입연산자를 사용하여 변수에 값 할당
| # 변수 선언 및 값 할당 a = 10 b = 20.5 c = "Hello, Python!" # 변수 출력 print(a) # 출력: 10 print(b) # 출력: 20.5 print(c) # 출력: Hello, Python! |
- 변수 타입: 파이썬에서는 다양한 타입의 변수를 사용할 수 있다. 변수의 타입은 할당된 값에 따라 자동으로 결정
| # 정수형 변수 integer_var = 100 print(type(integer_var)) # 출력: <class 'int'> # 실수형 변수 float_var = 25.4 print(type(float_var)) # 출력: <class 'float'> # 문자열 변수 string_var = "Python" print(type(string_var)) # 출력: <class 'str'> # 불리언 변수 bool_var = True print(type(bool_var)) # 출력: <class 'bool'> |
- 변수 이름 규칙
- 변수 이름은 영문자(대소문자 구분), 숫자, 밑줄(_)로 구성될 수 있다.
- 변수 이름은 숫자로 시작할 수 없다.
- 변수 이름은 공백을 포함할 수 없다.
- 변수 이름은 대소문자를 구분한다.
- 변수 값 변경: 변수는 새 값을 할당하면 이전 값은 사라지고 새로운 값으로 대체된다
| # 변수 값 변경 counter = 10 print(counter) # 출력: 10 counter = 15 print(counter) # 출력: 15 counter = counter + 5 print(counter) # 출력: 20 |
- 여러 변수에 한 번에 값 할당
| # 여러 변수에 한 번에 값 할당 x, y, z = 1, 2, 3 print(x, y, z) # 출력: 1 2 3 # 동일한 값을 여러 변수에 할당 a = b = c = 100 print(a, b, c) # 출력: 100 100 100 |
- 변수 삭제: del 키워드를 사용하여 변수를 삭제할 수 있다. 변수를 삭제하면 더 이상 해당 변수에 접근할 수 없다.
| # 변수 삭제 var = 10 print(var) # 출력: 10 del var # print(var) # 에러 발생: NameError: name 'var' is not defined |
# 연습문제 (예제풀이)
- 문자열 결합 : 두 개의 문자열 변수를 선언하고, 이들을 결합하여 출력하세요.
| str1 = "Hello" str2 = "World" combined = str1 + " " + str2 print(combined) |
- 사칙연산 : 두 변수 num1과 num2에 각각 15와 4를 할당한 후, 덧셈, 뺄셈, 곱셈, 나눗셈 결과를 출력하세요.
| num1 = 15 num2 = 4 print(num1 + num2) print(num1 - num2) print(num1 * num2) print(num1 / num2) |
2) 내장 자료형(Built in Data type): 내장 자료형을 통해 다양한 형태의 데이터를 다룰 수 있다.
- 정수: 소수점이 없는 숫자
- 부동 소수점: 소수점을 포함한 숫자
- 복소수: 실수부와 허수부를 가진 숫자 (ex. z = 3 + 4j)
- 문자열: 문자들의 집합으로, 작은따옴표 '' 또는 큰따옴표 ""로 묶는다. (ex. text = "Hello, World!")
- 리스트 (List): 순서가 있는 변경 가능한 자료형([ ])
| fruits = ["apple", "banana", "cherry"] fruits.append("orange") |
- 튜플 (Tuple): 순서가 있는 변경 불가능한 자료형 (( ))
| fruits = ("apple", "banana", "cherry") |
- 세트 (Set): 순서가 없고 중복을 허용하지 않는 자료형 ({})
| fruits_set = {"apple", "banana", "cherry"} fruits_set.add("orange") |
- 딕셔너리 (Dictionary): 키-값 쌍의 집합
| person = {"name": "Alice", "age": 30, "city": "New York"} person["job"] = "Engineer" |
- 부울형 (Boolean Type): 참(True)과 거짓(False)을 나타내는 자료형
| is_sunny = True is_raining = False |
- None 타입: 아무 값도 없음을 나타내는 특별한 자료형(ex. x = None)
# 연습문제 (예제풀이)
- 튜플 문제: 문자열 "apple", "banana", "cherry"를 포함하는 튜플을 생성하고, 두 번째 요소를 출력하세요.
| fruits = ("apple", "banana", "cherry") print(fruits[1]) # 두 번째 요소 출력 (0부터 숫자 센다!!!!) |
- 딕셔너리 문제: "name"을 키로 "Alice", "age"를 키로 30을 가지는 딕셔너리를 생성하고 "city" 키를 추가하여 "New York"을 설정한 후 출력하세요.

3) 조건문 (Conditional Statements): 특정 조건에 따라 코드 블록을 실행하거나 실행하지 않도록 제어하는 프로그래밍 구조
- 기본적인 if 문: if 문은 조건이 참인 경우에만 코드를 실행
| x = 10 if x > 5: print("x는 5보다 큽니다.") |
- if-else 문: if 문의 조건이 거짓일 때 대체 실행할 코드를 else 문을 사용하여 지정할 수 있다
| x = 3 if x > 5: print("x는 5보다 큽니다.") else: print("x는 5보다 작거나 같습니다.") |
- if-elif-else 문: 하나 이상의 조건을 체크해야 할 경우 elif (else if의 줄임말) 문을 사용
| x = 7 if x > 10: print("x는 10보다 큽니다.") elif x > 5: print("x는 5보다 큽니다.") else: print("x는 5보다 작거나 같습니다.") |
- 중첩된 조건문: 조건문 안에 조건문을 작성할 수 있다. 이를 통해 더 복잡한 조건을 처리할 수 있다
| x = 8 y = 6 if x > 5: if y > 5: print("x와 y는 모두 5보다 큽니다.") else: print("x는 5보다 크지만 y는 5보다 작습니다.") else: print("x는 5보다 작습니다.") |
- 논리 연산자와 함께 사용하는 조건문: 논리 연산자 and, or, not을 사용하여 여러 조건을 결합할 수 있다
| x = 4 y = 10 if x > 3 and y > 5: print("x는 3보다 크고 y는 5보다 큽니다.") if x > 5 or y > 5: print("x 또는 y 중 하나는 5보다 큽니다.") if not x > 5: print("x는 5보다 크지 않습니다.") |
- 비교 연산자와 함께 사용하는 조건문
| a = 10 b = 20 if a == b: print("a와 b는 같습니다.") elif a != b: print("a와 b는 다릅니다.") if a < b: print("a는 b보다 작습니다.") if a <= b: print("a는 b보다 작거나 같습니다.") if a > b: print("a는 b보다 큽니다.") if a >= b: print("a는 b보다 크거나 같습니다.") |
# 예제 풀이
- 성적에 따른 등급 출력

- 나이에 따른 요금 계산

- 로그인 시스템

3) 그로스마케팅 관련 예시
- 광고비 대비 전환율 평가
| # 변수 설정 ad_spend = 700000 # 광고비 (원) conversion_rate = 0.03 # 전환율 (3%) # 전환율 기준 평가 if conversion_rate >= 0.05: print("전환율이 우수합니다. 광고 전략을 유지하세요.") elif 0.03 <= conversion_rate < 0.05: print("전환율이 보통입니다. 최적화를 고려하세요.") else: print("전환율이 낮습니다. 광고 전략을 개선하세요.") |
- A/B 테스트 결과 비교
| # 변수 설정 conversion_A = 0.045 # A 캠페인 전환율 conversion_B = 0.052 # B 캠페인 전환율 # 조건문을 활용한 비교 if conversion_A > conversion_B: print("A 캠페인이 더 우수합니다.") elif conversion_A < conversion_B: print("B 캠페인이 더 우수합니다.") else: print("두 캠페인의 성과가 동일합니다.") |
- 방문자 수 대비 구매율 분석
| # 변수 설정 total_visitors = 5000 # 방문자 수 total_buyers = 250 # 실제 구매자 수 # 구매율 계산 및 분석 if total_visitors > 0: purchase_rate = (total_buyers / total_visitors) * 100 print(f"구매율: {purchase_rate:.2f}%") if purchase_rate >= 5: print("구매율이 우수합니다.") elif 2 <= purchase_rate < 5: print("구매율이 평균 수준입니다.") else: print("구매율이 낮습니다. 마케팅 전략을 조정하세요.") else: print("방문자 수가 0이므로 구매율을 계산할 수 없습니다.") |
- ROAS (광고 수익률) 분석
| # 변수 설정 ad_spend = 800000 # 광고비 (원) revenue = 4000000 # 광고를 통해 발생한 매출 (원) # ROAS 계산 및 평가 if ad_spend > 0: roas = (revenue / ad_spend) * 100 print(f"ROAS: {roas:.2f}%") if roas >= 400: print("ROAS가 우수합니다. 광고 전략을 유지하세요.") elif 200 <= roas < 400: print("ROAS가 평균 수준입니다. 개선할 여지가 있습니다.") else: print("ROAS가 낮습니다. 광고 전략을 조정하세요.") else: print("광고비가 0원이므로 ROAS를 계산할 수 없습니다.") |
- 고객 리뷰 감성 분석 후 응답 자동화
| # 변수 설정 customer_review = "배송이 너무 늦고 제품도 마음에 안 들어요." review_score = 2 # 고객이 남긴 별점 (1~5) # 리뷰에 따른 응답 설정 if review_score >= 4: response = "고객님, 좋은 평가 감사합니다! 앞으로도 만족을 드리겠습니다. 😊" elif 2 <= review_score < 4: response = "소중한 의견 감사드립니다. 더 나은 서비스를 위해 노력하겠습니다!" else: response = "불편을 끼쳐드려 죄송합니다. 고객님의 의견을 바탕으로 개선하겠습니다. 🙏" # 자동 응답 출력 print(response) |
- 광고 예산 설정 및 캠페인 전략 조정
| # 변수 설정 monthly_budget = 1200000 # 월간 광고 예산 (원) # 광고 전략 추천 if monthly_budget >= 5000000: strategy = "프리미엄 캠페인 (SNS, 유튜브 광고 포함)" elif 2000000 <= monthly_budget < 5000000: strategy = "중간 규모 캠페인 (구글 & 페이스북 광고 중심)" elif 1000000 <= monthly_budget < 2000000: strategy = "소규모 캠페인 (네이버 블로그 & 인스타그램 활용)" else: strategy = "저비용 바이럴 마케팅 (SNS 인플루언서 협업)" # 전략 출력 print(f"현재 예산으로 추천되는 마케팅 전략: {strategy}") |
2. Python 데이터 구조
: Python에서는 다양한 데이터 구조(Data Structures)를 제공하여 데이터를 효율적으로 저장하고 관리할 수 있다.
- 리스트(List) - 순서가 있는 변경 가능한(뮤터블) 배열
- 튜플(Tuple) - 순서가 있는 변경 불가능한(이뮤터블) 배열
- 딕셔너리(Dictionary) - 키-값 쌍으로 구성된 해시 맵 자료형
- 집합(Set) - 중복이 없는 요소를 저장하는 구조
1) 리스트 (List): 순서가 있는 변경 가능한 데이터 구조. 대괄호 []를 사용하여 리스트를 정의하며, 인덱스(Index)를 통해 요소에 접근할 수 있다.
- 리스트 생성 및 기본 사용법
| # 리스트 생성 campaigns = ["봄맞이 할인", "여름 세일", "가을 이벤트", "겨울 프로모션"] # 리스트 요소 접근 (인덱스 사용) print(campaigns[0]) # '봄맞이 할인' print(campaigns[-1]) # '겨울 프로모션' (음수 인덱스는 뒤에서부터 접근) |
- 리스트 요소 수정 및 추가
| # 리스트 요소 변경 campaigns[1] = "여름 할인" print(campaigns) # ['봄맞이 할인', '여름 할인', '가을 이벤트', '겨울 프로모션'] # 리스트에 새로운 요소 추가 campaigns.append("봄 시즌 프로모션") print(campaigns) # ['봄맞이 할인', '여름 할인', '가을 이벤트', '겨울 프로모션', '봄 시즌 프로모션'] |
- 리스트 삭제
| # 특정 요소 삭제 del campaigns[2] # '가을 이벤트' 삭제 print(campaigns) # ['봄맞이 할인', '여름 할인', '겨울 프로모션', '봄 시즌 프로모션'] # 리스트 전체 삭제 campaigns.clear() print(campaigns) # [] |
- 리스트 반복문 활용
| # 리스트의 각 요소 출력 for campaign in campaigns: print(f"캠페인: {campaign}") |
- 리스트 슬라이싱
| # 리스트 일부 가져오기 print(campaigns[1:3]) # 인덱스 1부터 3 이전까지의 요소 가져오기 |
2) 튜플 (Tuple): 순서가 있지만 변경할 수 없는 데이터 구조. 소괄호 ()를 사용하여 정의. 데이터가 변경되지 않도록 보장해야 할 때 사용
- 튜플 생성 및 요소 접근
| # 튜플 생성 marketing_channels = ("Google Ads", "Facebook Ads", "Email Marketing") # 요소 접근 print(marketing_channels[0]) # 'Google Ads' print(marketing_channels[-1]) # 'Email Marketing' |
- 튜플의 주요 특징:
- 튜플은 한 번 생성되면 수정할 수 없다
- 불변성을 유지해야 하는 데이터에 적합
- 리스트보다 메모리 사용량이 적고 속도가 빠름
- 해싱 가능 → 딕셔너리의 키로 사용 가능
3) 딕셔너리 (Dictionary): 키(Key)와 값(Value) 쌍으로 이루어진 데이터 구조. 중괄호 {}를 사용하여 정의하며, 각 키를 통해 값을 빠르게 조회할 수 있다.
- 딕셔너리 생성 및 요소 접근
| # 딕셔너리 생성 campaign_performance = { "봄맞이 할인": {"CTR": 0.12, "CR": 0.05}, "여름 세일": {"CTR": 0.15, "CR": 0.07}, "가을 이벤트": {"CTR": 0.08, "CR": 0.03} } # 특정 키의 값 조회 print(campaign_performance["봄맞이 할인"]) # {'CTR': 0.12, 'CR': 0.05} |
- 딕셔너리 요소 추가 및 수정
| # 새로운 캠페인 데이터 추가 campaign_performance["겨울 프로모션"] = {"CTR": 0.10, "CR": 0.06} # 기존 캠페인 데이터 수정 campaign_performance["봄맞이 할인"]["CTR"] = 0.13 |
- 딕셔너리 반복문 활용
| for campaign, metrics in campaign_performance.items(): print(f"{campaign}: 클릭률 {metrics['CTR']}, 전환율 {metrics['CR']}") |

4) 집합 (Set): 중복을 허용하지 않는 데이터 구조. 중괄호 {}를 사용하여 정의하며, 빠른 검색과 중복 제거에 유용
- 집합 생성 및 활용
| # 집합 생성 active_users = {"user1", "user2", "user3"} new_users = {"user2", "user3", "user4", "user5"} # 합집합 (Union) all_users = active_users | new_users # {'user1', 'user2', 'user3', 'user4', 'user5'} # 교집합 (Intersection) common_users = active_users & new_users # {'user2', 'user3'} |
- 집합의 주요 특징:
- 중복 요소 제거: 리스트보다 고유한 값만 저장할 때 유용
- 순서 없음: 리스트와 달리 인덱스로 접근 불가
- 빠른 검색 및 연산 지원: 해시 기반 구조로 검색 속도가 빠름
3. 반복문 (Loops)
특정 코드 블록을 여러 번 실행하도록 하는 제어 구조. 파이썬에서는 주로 for 반복문과 while 반복문을 사용. 반복문은 코드의 재사용성을 높이고, 반복 작업을 자동화하는 데 매우 유용하다.
1) for 반복문: 시퀀스(리스트, 튜플, 문자열 등)의 각 항목에 대해 반복을 수행
- 기본 구조
| for 변수 in 시퀀스: 실행할 코드 |
- 리스트의 각 항목 출력

- 딕셔너리의 키와 값 출력

2) while 반복문: 조건이 참일 동안 코드를 반복 실행
- 기본 구조
| while 조건: 실행할 코드 |
- 숫자 세기
| count = 0 while count < 5: print(count) count += 1 |
- 사용자 입력에 따른 반복

3) 반복문 제어
- break: 반복문을 즉시 종료
| for i in range(10): if i == 5: break print(i) |
- continue: 반복문의 나머지 부분을 건너뛰고 다음 반복을 진행

- else: 반복문이 정상적으로 종료된 후에 실행되는 코드 블록 (break로 종료되지 않았을 때 실행).
| for i in range(5): print(i) else: print("반복이 끝났습니다.") |
# 예제 풀이
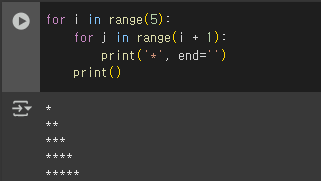
- 중첩 반복문을 사용한 별 모양 출력
- 사용자로부터 문자열을 입력받아 모음과 자음의 개수를 세어 출력하는 프로그램을 작성하세요

- 여러 학생의 점수를 입력받아 평균을 계산하고 출력하는 프로그램을 작성하세요.

4. Python 함수와 클래스, 모듈과 패키지
1) 함수 (Functions)
: 함수는 특정 작업을 수행하는 코드 블록이다. 함수는 코드의 재사용성을 높이고, 프로그램의 구조를 더 명확하게 만들어준다. 파이썬에서 함수는 def 키워드를 사용하여 정의한다.
(1) 함수 정의와 호출
- 기본 구조
| def 함수이름(매개변수1, 매개변수2, ...): 실행할 코드 return 반환값 |
- 두 숫자의 합을 계산하는 함수
| def add(a, b): return a + b result = add(3, 5) print(result) # 출력: 8 |
- 키워드 인수를 출력하는 함수

(2) 함수 내 함수: 함수 내에서 다른 함수를 정의할 수 있다.
- 함수 내 함수를 사용하는 예제
| def outer_function(text): def inner_function(): print(text) inner_function() outer_function("Hello from the inner function!") |
(3) 람다 함수: 익명 함수로, 한 줄로 간단히 표현할 수 있는 함. lambda 키워드를 사용
- 두 숫자의 합을 구하는 람다 함수
| add = lambda x, y: x + y print(add(3, 5)) # 출력: 8 |
# 예제 풀이
- 리스트의 중복 요소 제거
| def remove_duplicates(lst): return list(set(lst)) print(remove_duplicates([1, 2, 2, 3, 4, 4, 5])) # 출력: [1, 2, 3, 4, 5] |
- 리스트의 최대값과 최소값을 반환하는 함수
| def find_max_min(lst): return max(lst), min(lst) max_val, min_val = find_max_min([1, 2, 3, 4, 5]) print(f"최대값: {max_val}, 최소값: {min_val}") # 출력: 최대값: 5, 최소값: 1 |
- 주어진 두 숫자 범위 내의 모든 숫자의 합을 계산하는 함수 sum_range(start, end)를 작성하세요.
| def sum_range(start, end): total = 0 for num in range(start, end + 1): total += num return total print(sum_range(1, 10)) # 출력: 55 |
2) 클래스 (Class)
- 객체 지향 프로그래밍의 기본 구성 요소로, 객체를 생성하기 위한 청사진(또는 템플릿)이다.
- 클래스는 데이터와 그 데이터를 처리하는 메서드를 하나로 묶어서 관리할 수 있게 해준다.
- 클래스는 속성(데이터)과 메서드(기능)로 구성한다.
- 클래스의 기본 구조
- __init__: 생성자 메서드로, 클래스의 인스턴스가 생성될 때 자동으로 호출됩니다. 이 메서드를 통해 초기 속성을 설정할 수 있다.
- self: 클래스의 인스턴스를 가리키는 참조 변수입니다. 메서드 정의 시 첫 번째 매개변수로 항상 self를 포함해야 한다.
| class 클래스이름: def __init__(self, 매개변수1, 매개변수2, ...): self.속성1 = 매개변수1 self.속성2 = 매개변수2 ... def 메서드이름(self, 매개변수1, 매개변수2, ...): 실행할 코드 |
- 예제 1: 기본 클래스 - 클래스 정의와 인스턴스 생성
| class Person: def __init__(self, name, age): self.name = name self.age = age def greet(self): print(f"안녕하세요, 제 이름은 {self.name}이고, 나이는 {self.age}살입니다.") # 인스턴스 생성 person1 = Person("Sumi", 30) person2 = Person("Charls", 25) # 메서드 호출 person1.greet() # 출력: 안녕하세요, 제 이름은 Sumi이고, 나이는 30살입니다. person2.greet() # 출력: 안녕하세요, 제 이름은 Charls이고, 나이는 25살입니다. |
- 예제 2: 클래스의 속성과 메서드 - 클래스 속성 변경 및 메서드 추가

- 예제 3: 상속( 상속을 통해 기존 클래스의 속성과 메서드를 물려받아 새로운 클래스를 정의할 수 있다)
- 기본 클래스와 서브 클래스

- 예제 4: 클래스 변수와 인스턴스 변수 (클래스 변수는 클래스 전체에서 공유되며, 인스턴스 변수는 각 인스턴스마다 독립적으로 존재)

- 예제 5: 특수 메서드 (파이썬에서 미리 정의된 메서드로, 클래스의 특정 기능을 변경하거나 확장할 때 사용한다. 예를 들어, __str__, __repr__, __len__ 등이 있다. )

- 예제 6: 학생 관리 클래스
| class Student: def __init__(self, name, student_id): self.name = name self.student_id = student_id self.grades = [] def add_grade(self, grade): self.grades.append(grade) def average_grade(self): return sum(self.grades) / len(self.grades) # 인스턴스 생성 student = Student("Sumi", 12345) # 성적 추가 student.add_grade(90) student.add_grade(85) student.add_grade(92) # 평균 성적 출력 print(f"{student.name}의 평균 성적: {student.average_grade()}") # 출력: Sumi의 평균 성적: 89.0 |
3) 모듈과 패키지
- 모듈: 파이썬 파일(.py)은 모듈로 간주됩니다. 모듈에는 함수, 클래스, 변수 등이 포함될 수 있다.
- 패키지: 디렉토리 구조로 조직된 여러 모듈을 패키지라고 합니다. 패키지에는 __init__.py 파일이 포함되어 있어야 한다.



